架构特点
AMD RX6600 XT基于AMD最新的RDNA2架构,使用的RDNA2架构中的第三款核心Navi23的完整版。
Navi23的核心规格和Navi22比较接近,因为都是两SE,所以前端、光栅器和ROP都保持了相同的规格,但SE中Navi22拥有5组WGP,也就是10CU,Navi23只有4组,8CU。除开这两个硬规格,Navi23中和Navi22最大的不同点其实是在内存子系统。Navi22有192bit显存位宽,而Navi23只有128bit显存位宽,Infinity Cache上Navi22有96M,而Navi23仅有32M。
Infinity Cache是一个内存侧缓存,它可以在不影响原有架构的缓存设计的情况下,为GPU额外增加一级GPU不可见的缓存。在显存带宽发展速度已经严重落后于核心规模增加速度的今天,一个额外的缓存提供的带宽非常的重要。但片上缓存所用的SRAM是昂贵的,即便采用了类似CPU上L3缓存的低速设计,依然需要非常多的晶体管,7nm下每32M缓存大约需要34平方毫米。
这里我们需要考虑一下等效带宽的计算,AMD给出算法是缓存带宽*命中率+GDDR6的带宽,但我认为这是错误的算法。假设一个缓存在目标分辨率下的命中率是50%,缓存本身可以提供2000GiB/s带宽,GDDR6可以提供512GiB/s的带宽,传输数据量总共1000GiB,那么命中部分的数据量500GiB,可以在500GiB/2000GiB/s,也就是1/4s内完成,而未命中部分则需要500GiB/500GiB/s,也就是1s内完成,假设两者可以同时传输数据,那么缓存部分最终需要等待GDDR6部分,带宽也就是1000GiB/1s = 1000GiB/s。所以其实公式应该是,min(缓存带宽,GDDR6带宽/(1-命中率))。
| 等效带宽GiB/s | IC理论带宽 | 2160p | 1440p | 1080p |
| Navi21 | 1940 | 1219 | 1706 | 1940 |
| Navi22 | 1293 | 768 | 1041 | 1293 |
| Navi23 | 970 | 336 | 399 | 539 |
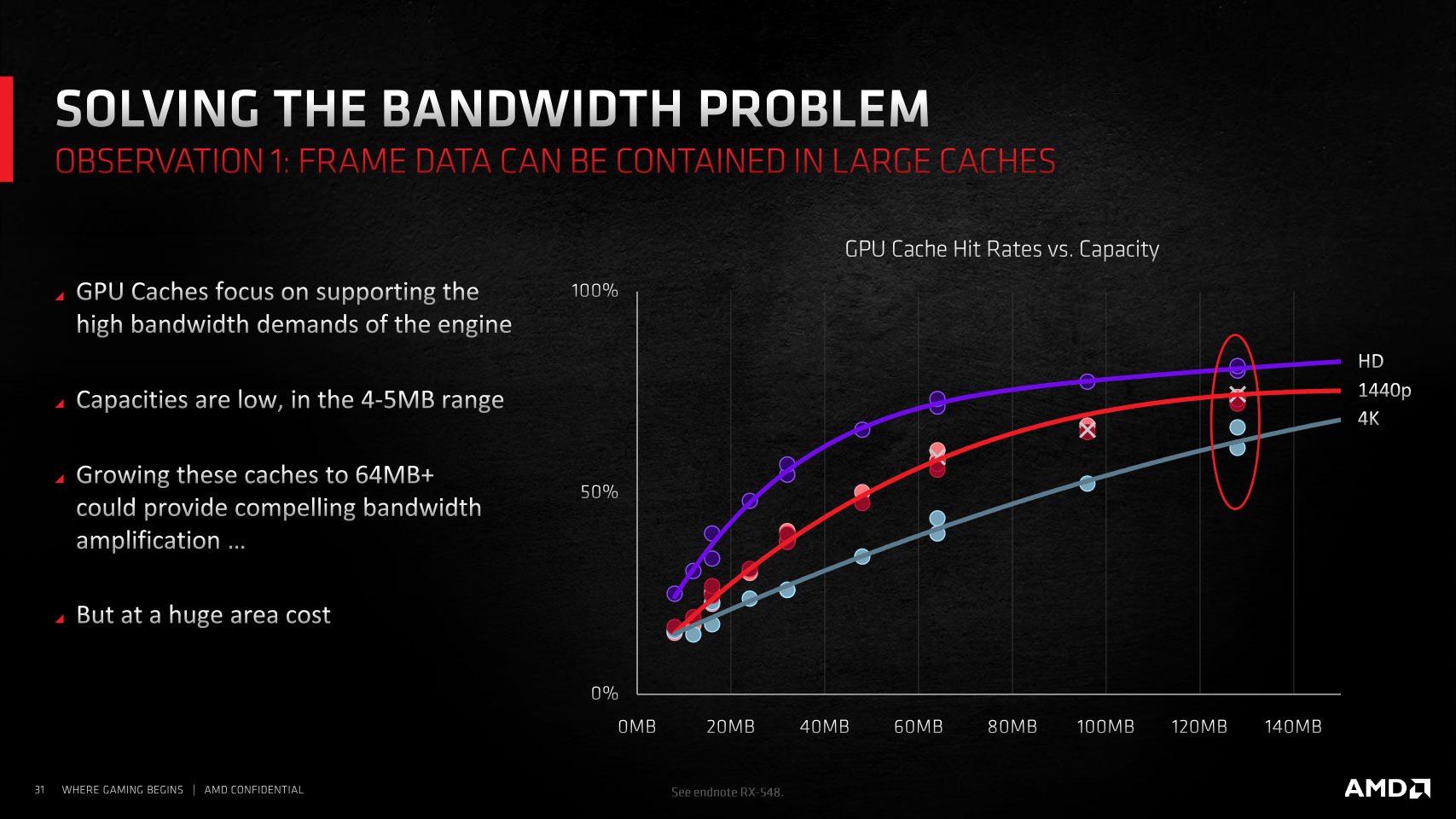
我们可以看到无论Navi21的带宽基本可以完全满足所有分辨率情形,而Navi22稍弱,4K下有点勉强,而Navi23,Infinity Cache直接减少到32M,4K和2K分辨率下,带宽都不足,只有在1080p下是比较合适的。所以这也就点明了这次测试的重点,1080p。
性能测试
测试平台:
| CPU | AMD Ryzen 7 5800X |
| 主板 | ASUS PRO WS X570 ACE |
| 内存 | 皇家戟 3200 C16 OC 3800 |
| 显卡 | 盈通 RX6600 XT |
| 声卡 | 创新 AE9 |
| 散热器 | FS140 |
本次测试分辨率均为1080p:

可以看到,6600XT虽然规格更低,但在1080p分辨率下凭借高频优势,在非光追模式下,几乎和上一代旗舰5700XT的成绩完全相等,比2080只略弱%5左右,对于本代的中低端芯片来说已经是非常不错的成绩了。而对于光追模式,6600XT就有点吃力了,和2080都有相当大的差距,不过这也不代表光追就完全没用,在Dirt5和GodFall这类优化很好的光追游戏里面,6600XT依然可以以相当流畅的帧数运行。
功耗测试

6600XT的功耗非常低,最大功耗应该是被死死的限制在了130W以下,对比5700XT的190w左右和2080的220w,可谓是相当的出众了。即便考虑上性能问题(排除光追),能耗比也领先2080高达56.8%。之前测试中,6700XT的功耗大约185w左右,6600XT也是和它拉开了很大的差距的,这种差距的来源,一小部分来自核心规格的降低,另一大部分来1080p下,恰好合适的32M缓存,SRAM虽然帮助节约了GPU访问GDDR6产生的功耗,但是SRAM本身的功耗也不可小视,特别是IC这种大带宽的缓存。减少64M不仅帮助AMD将6600XT的定位明确下来,也帮助6600XT在能耗比上有了一个大的飞跃。
噪音测试
盈通这块6600XT工作的时候非常安静,对于我生活环境而言,即便我选择在凌晨进行测试,也无法在15CM的距离上测得高于背景噪音的数据,所以这次的数据就不放了。
总结
最近的Steam硬件调查显示,1080p依然以67%的占比统着绝对主流的游戏玩家的屏幕分辨率,这次AMD推出的6600XT则是完美的针对了绝大部分玩家的需求,安静、凉快、低功耗、但又性能十足,完美的1080p显卡。