







性能测试:6800XT vs 3080 FE vs 5700XT
测试平台:
| CPU | 5950X |
| 主板 | Asus Pro WS X570 ACE |
| 内存 | 皇家戟 3200 C16 OC 3600 |
| 显卡 | RX 6800 XT,RX 5700 XT,RTX3080 FE |
| 声卡 | 创新 AE9 |
| 散热器 | 银欣 IG280 |
游戏性能实测
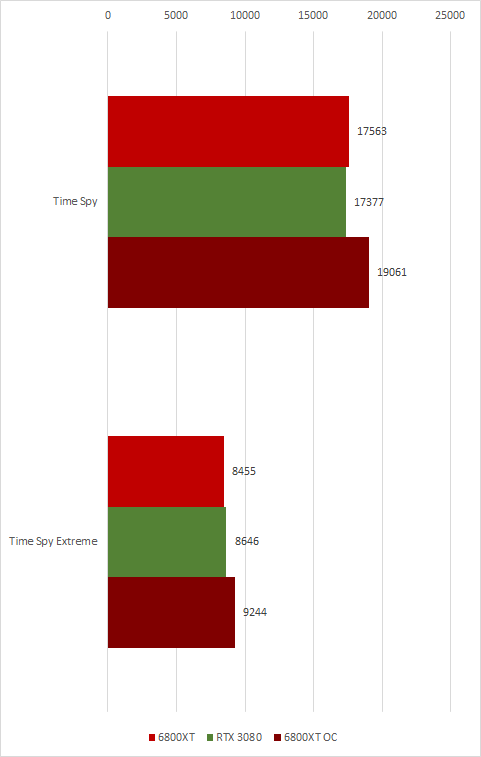
上次CPU测试,我把架构部分放在最前面,导致很多朋友昏昏欲睡,所以这次我把性能测试放在最前面,直接上图,游戏测试均使用2K分辨率(穷买不起4K显示器),6800XT打开SAM,但不使用Rage模式:

在传统网游中,由于GPU的已经不再是瓶颈,所以性能区别不大。但得益于驱动优化更好,6800XT和5700XT在LOL的测试中,最低FPS明显领先于3080 FE。
单机游戏测试,我都是选择了一些自己常玩的游戏,然后加入了银河破碎者这个支持光线追踪,也支持VRS的游戏来进行一些性能上的分析。
传统渲染模式下,按百分比综合下来,大约领先5%,大概半档的差距。在AMD绝对性能落后数年之后。第一次,在最高端芯片的正面战场打赢了竞争对手的产品,可以说是AMD在图形市场上的翻身一击。
在特别挑选的银河破碎者中,VRS开的时候6800XT大约比关的时候强出8.5%,而竞争对手则领先大约8%,6800XT略胜一筹。5700XT因为不支持VRS,强行打开之后甚至出现了一定程度的性能下降。
光追渲染中,6800XT落后较多,差距在14%。
同样在银河破碎者中,在光追打开的时候,VRS不仅没有提升性能,反而两张卡都出现了性能下降。看来VRS并不是一个缓解光追性能问题的好办法。随后我测试了开关不同光追特效时的性能,关闭光追阴影,只保留光追AO的时候,6800XT的性能出现了反超。而关闭AO打开阴影的时候,性能比例又回归正常。看来对于高负载的光追,AMD的适应能力较弱。之后我会补充2080的测试,更加细致的分析一下这个问题。
传统跑分以及超频测试:

3Dmark跑分中可以看到在老一点的FSE中6800XT大幅领先,而Timespy中,得益于架构和频率双方的提升,也追平了甚至稍微超过了3080。在4K分辨下测试所需的数据量更大,6800XT的InfiniteCache 缓存命中率比2K低一些,所以性能上又被3080稍微追回一点。
当然这不是RDNA2架构的全部实力。AMD的驱动调节上限为2.8Gh核心峰值,2150Mhz显存,+15%功耗。
实际超频时,默认电压状态,可以轻易的将功耗和显存拉到头,对于高负载的游戏,频率可以拉到2.7Ghz,需要注意的是,高负载状态实际工作频率远没有2.7Ghz那么高,更具具体游戏不同,最高可以稳定在2.55Ghz左右。
低负载游戏,核心频率上限就不能给那么高了,因为游戏过程中真的会Boost到峰值,导致黑屏。我的建议是默认电压下,将核心频率控制在2.65Ghz,让低负载游戏不至于Boost过高,导致不稳定。
需要压榨极限性能的时候,AMD的+15%功耗就成为了最大的限制,我们需要将电压降低,来榨取每一分的性能。我测试中最佳状态为2.6Ghz Boost上限,电压从1.15v降低到1.05v,风扇上限75%,别的拉满。3dmark Time Spy烤鸡过程中,温度可以维持在68°左右,实际工作频率上限2.43Ghz。下面是跑分:
分别提升了8.5%和9%的性能,按比例算应该已经游戏性能已经超过了3090。非公如果可以开放功耗限制,估计能再上一个台阶。
性能测试就到此结束。
总结一下,传统图形性能较3080有明显优势,TDP却比3080低20W,在光追游戏还远远没有普及的时代,400块的价格优势,怎么说,6800XT就是比3080更香的那种味道!!
RDNA2架构解析

RDNA2 CU架构
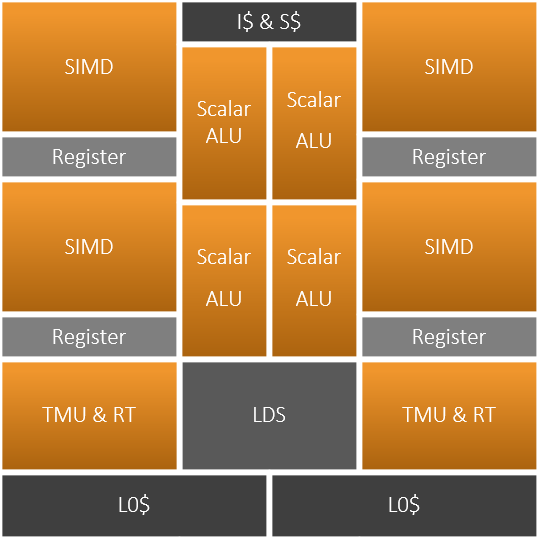
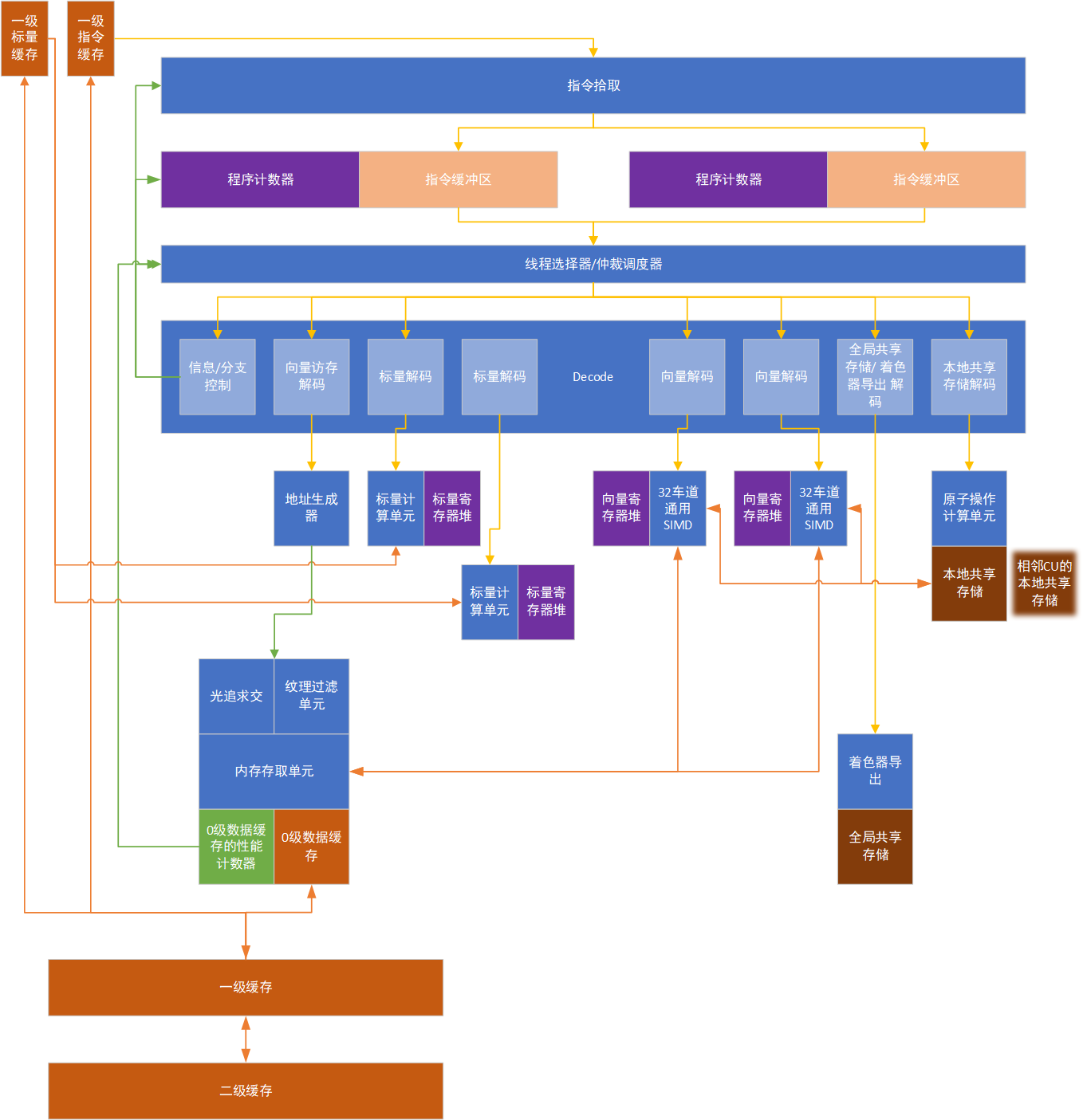
RDNA2的CU是RDNA系列的第一个改进版CU,RDNA2的整体CU架构相比于RDNA1的改动不大,最大的改进在于添加了一个硬件光追求交加速器。在细节上AMD表示RDNA2 CU的微架构更加的流水线化,为RDNA2 GPU的高频做好了准备。
AMD的CU或者Nvidia的SM是GPU内部最小的独立执行单元,是一个完整的处理器。CU与一般的处理器不同,它们是吞吐向的处理器,因为延迟不敏感,所以它们都采用了FGMT或者FGMT与CGMT并存的多线程技术。GPU中的硬件线程称为Wavefront或者Warp。与传统CPU上的SMT不同,FGMT与CGMT不保证各个线程同时执行,而是每周期切换或者遇到缓存未命中的时候切换执行的硬件线程。在RDNA2架构中,每个CU最多可以有32个Wavefront处于就绪状态,而一般的CPU只有2个。32个Wavefront被分为两组,进入CU时被储存在两个指令缓冲中,每组16个。程序计数器也被分为两组,每组16个。完美的情况下,调度器会从2个指令缓冲中分别找出2条向量SIMD指令送给2个对应的SIMD32执行单元,找出2条标量指令送给2个对应的标量ALU,其余对应向量访存、分支、LDS、GDS、EXPORT的指令,则从2组Wavefront中找出3个送给对应的执行单元。
RDNA的CU和GCN的CU不同,它的Wavfront宽度为32,GCN为64。它的向量SIMD执行单元宽度为32,延迟为5周期,吞吐率为1,也就是每周期可以对它发射1条向量指令,并完成1条向量指令,当前发射的向量指令会在5周期时生成结果。RDNA的CU中总计2个SIMD可以有2的吞吐率,每周期完成32*2个软件线程。
GCN中的SIMD单元宽度为16,延迟为4周期,吞吐率为0.25,也就是每4周期可以对它发射1条向量指令,并完成1条向量指令,当前发射的向量指令会在4周期时生成结果。GCN的CU中总计4个SIMD每周期完成64*1个软件线程。两者吞吐率一致。
GCN是精细设计的十分优美的架构,单一的向量SIMD发射端对应了4个4分之1吞吐率的SIMD,每个SIMD指令不会有指令执行时间的重叠,每个SIMD也有自己的寄存器,完美避免了寄存器相关的任何访问冲突和冒险,并且简化了编译器以及硬件的调度难度。但缺点也是有的,GCN总计可以维持10*4个Wavefront,总计2560个软件线程,2560个线程分享256KiB的寄存器以及64KiB的LDS等资源,每线程的LDS以及寄存器压力都较大,每个SIMD用于掩盖延迟的Wave数量也较少。在软件对寄存器需求极多的极端情况下,每SIMD仅能维持一个Wavefront,全CU总计4*64 = 256软件线程,对于GCN的CU这个单周期5发射的处理器来说,也就是最少只有1/5的利用率。
RDNA2则是比较灵活的设计,需要比较复杂的软件调度来检测不同指令之间的寄存器Bank冲突,将没有冲突的指令的排列在一起,以便互相掩盖延迟,尽可能达到1的吞吐率。RDNA的CU可维持2*20个Wavefront,总计1280个软件线程,1280个软件线程分享265KiB的寄存器和64KiB的LDS等资源,压力较GCN小一倍。在软件对寄存器需求几多的极端情况下,每SIMD依然可以维持至少4个Wavefront,全CU总计2*4*32 = 256软件线程,对于RDNA的7发射来说,最差的利用率也有5/7,并且由于RDNA的SIMD单周期发射,甚至还有空间选择通过ILP还是切换线程来维持SIMD的利用,灵活性更高。简而言之,RDNA在低软件线程数下,相对GCN有很大的优势。由于这种设计优势过于明显,以至于出现边际效应,所以AMD在RDNA2中将可维持的Wavefront数量上限从40降低到了32,节约了资源。
AMD在GCN中引入了1个功能强大的Scalar ALU。Scalar ALU主要完成分支和流程控制方面的操作,极大的提高了程序的灵活性,以及动态分支的性能。GCN中Scalar ALU只有1个,由4组Wavefront轮流共享。而RDNA因为单周期发射的原因,所以将Scalar ALU加到了两个,两组Wavefront独享。
CU中其他部分,由所有的两组Wavefront共享。
在RDNA2中,AMD引入了硬件光追加速器,每周期可以完成4个BVH求交和1个三角形求交,与Nvidia的图灵保持一致。与图灵一样,AMD的光追加速器也与TMU设计在一起,因为光追加速器与TMU一样,都是需要直接访存的部件,可以与LSU共享很多部件。从硬件上来看AMD的硬件光追加速器与TMU的耦合度更高,Navi10的TMU、L0总计面积大约0.67mm^2,而同样7nm的RDNA2上,加上光追加速器之后,面积仅仅稍微增长到0.757mm^2,约1.13倍。作为对比TU10x和TU11x,每TPC中的TMU部分从2.355mm^2增长到了3.095mm^2,约1.31倍。




从整个CU的角度来看,光追只付出了极低的代价,配合前面精简Wavefront数量,CU面积仅仅增加了0.09mm^2。
RDNA2缓存架构
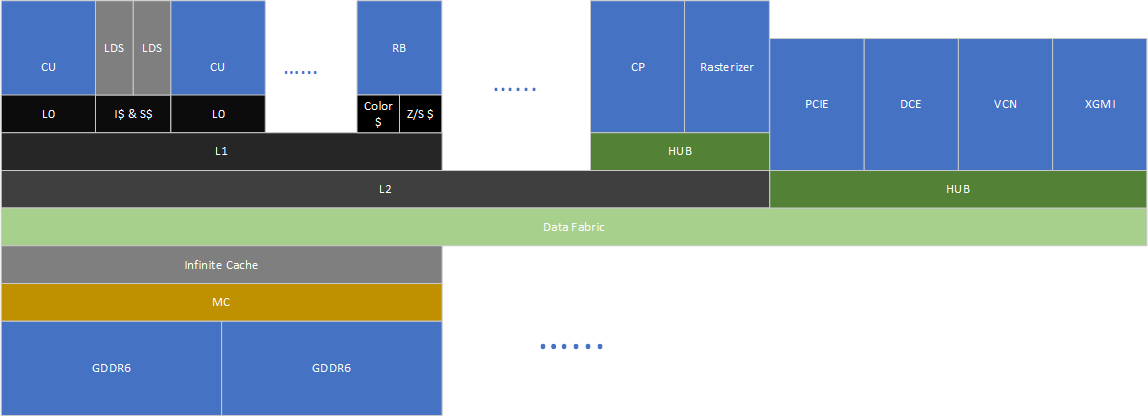
缓存层次结构是AMD架构中的改进重点。这是AMD在连续三代架构中对缓存下手了。在GCN5之前,RB作为独立的部件拥有自己的色和深度/模板缓存,直接与显存控制器相连,当Shader需要访问RB的渲染目标时,就需要走显存绕一圈,极大的耗费了功耗与带宽。GCN5中AMD将RB的访存路径移到了L2缓存之上,这样当Shader需要访问渲染目标的时候,可以在片上走L2完成,大大节约了功耗,并且得益于L2的低延迟和大带宽,性能也有不少提升。在RDNA架构中,AMD将原来的L1数据缓存作为CU私有的L0缓存,增加了一倍的带宽,然后在SA中增加了一块128 KiB的L1缓存。同一块SE中通常执行类似的任务,数据相关性较大,新增加的L1缓存不需要过大就能获得较高的命中率,显著降低了延迟。同时SA中的CU之间,CU与RB之间,交换数据的路径更加简短,功耗上可以因此获益。
RDNA2中,AMD在MC与SDF之间增加了一级容量高达128MiB的Infinite Cache作为内存侧缓存,这是GDDR6时代,显存功耗与布线复杂性双重威胁下做出的妥协。Infinite Cache作为内存侧缓存,不需要极低的延迟,它需要的是足够的容量以及足够的带宽来应对GPU海量的访存需求。现代游戏的显存访存足迹都非常大,2K下几乎没有多少低于4GiB的,128MiB的容量在巨大的访存足迹下显得捉襟见肘,但好在访存足迹虽然大,不过热点数据其实远小于访存足迹,根据AMD的说法,在4K下128MiB通常有接近60%的命中率,这可以极大的降低显存带宽的压力。不过根据我的观察,4K下整个GPU的性能依然对显存带宽比较敏感,似乎没有完全解决带宽压力。
这里我写了一个简单的OpenCL测试程序用于带宽测试:
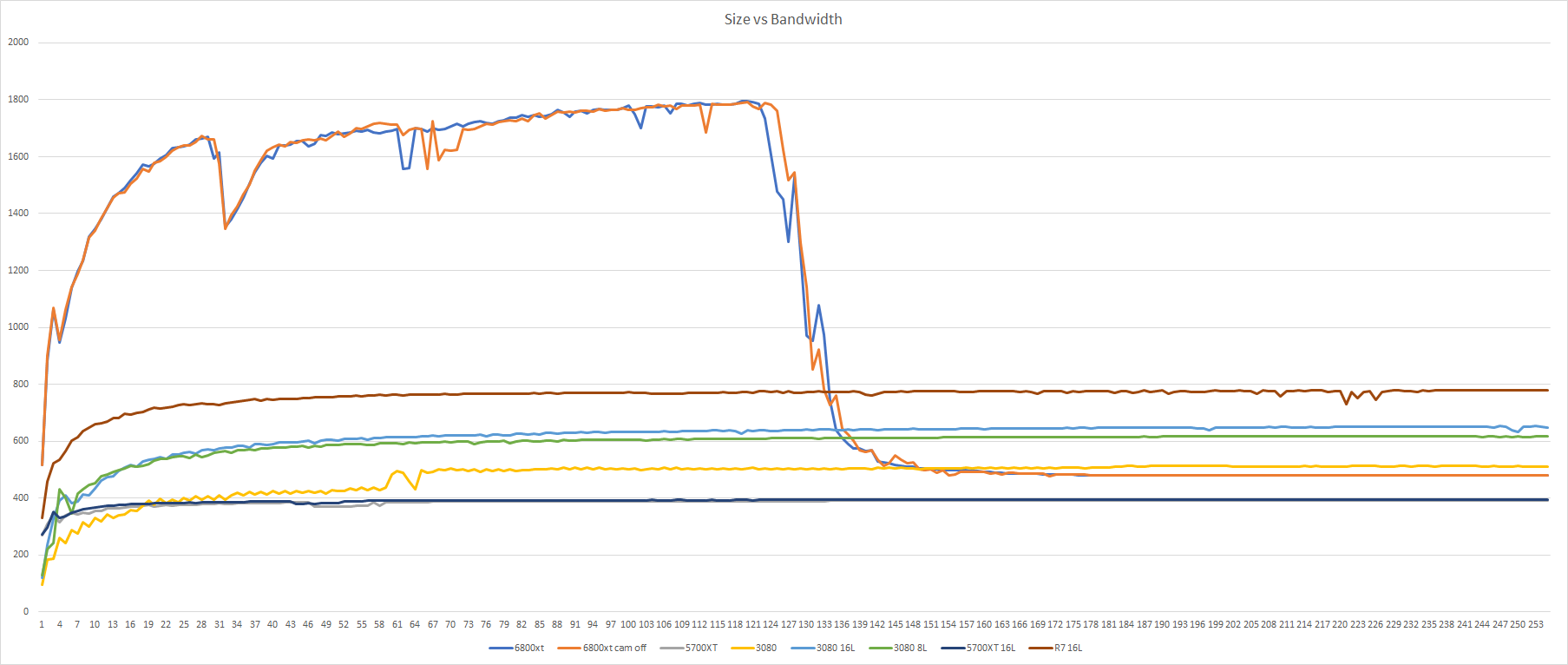
程序中每个软件线程,有32个访存操作,共计读取一块Buffer中32个浮点数,每个软件线程中访问的地址与任意其他线程访问的地址均不存在覆盖。每次测试会创建固定数量的软件线程用于产生足够大的访存足迹,比如8192条线程可以产生,8192 * 32 float * 4Byte/float = 1MiB的足迹。经过多次循环,记录用时,便可求得带宽。这次测试足迹从1MiB开始每次增加1MiB,直到256MiB结束。
测试中可以明显的看到,在128MiB之前,得益于Infinite Cache,6800XT都有着出类拔萃的表现,即便面对4片HBM2的R7也有着一倍以上的带宽优势,峰值带宽达到了1.8TiB/s。在128MiB之后,6800XT则回归正常,最终由GDDR6提供了480GiB/s的有效带宽,如果按AMD58%的命中率来看,4K游戏下,整个显存系统可以提供高达,1.524TiB/s的带宽,。有观众可能会问,为什么L2带宽在图中没有体现出来,那是因为线程数较低的时候,不足以喂饱CU,比如8192个线程仅能对应256个Wavefront,仅够喂饱8个CU。
看完带宽,我们再来看看延迟,延迟测试我直接使用Sisoftware进行:

由于Sisoftware的识别问题日,我们无法测得更高容量下的延迟,所有延迟均到32MiB结束。测试显卡中5700XT、R7、2080均运行在1.8Ghz,3080运行在1.71Ghz,6800XT运行在2.05Ghz。运行频率对于片上缓存的延迟周期没有影响,但对显存和非同频运行的Infinite Cache的表现有所影响,频率更高的卡,同延迟时间下,周期数更多。
这里可以看到L1(RDNA L0)缓存延迟最低的是GCN架构的R7,它的L1容量较小,并且带宽较低,RDNA架构的L0虽然容量没有变化,但带宽让它付出了一些延迟上的代价。RDNA独有的L1缓存,让容量差距巨大的L2和L0缓存之间的延迟有了一个更加平顺的过渡。在RDNA2中,AMD表示因为更加流线型的TLB设计让缓存的延迟更低,在L1和L2身上也得到了体现,L1延迟下降。L2缓存的延迟,RDNA的5700XT在2MiB开始就稍微有所上升,RDNA2的6800XT则在满容量的4MiB才开始,这应该也是TLB优化的结果。
内存侧缓存Infinite Cache虽然主要是为了提供足够的带宽,不过这里可以看到对于延迟同样有了不少的优化。换算成ns数的话大约91ns,使用HBM2的R7延迟大约110ns,GDDR6的5700XT和2080延迟类似,分别为148和146ns。而GDDR6X的表现最为糟糕为178ns,几乎两倍于Infinite Cache。
RDNA2图形架构
RDNA2的图形架构可以参看前面Overview的那张图。硬件上,AMD对几何引擎,光栅器,已经Render Backend都做出了不少的修改。
进入DX12U的时代,微软对于图形流水线的几何部分做出了重要的改进。
微软使用Amplification Shader和Mesh Shader取代了原有的几何流水线,赋予程序员更加灵活高效的顶点以及图元处理能力。作为最早对这部分动手的AMD,确也是在这条路上走的最不顺的厂家。在Vega时代,前端数量难以提升的AMD就打算引入一个Primitive Shader和Surface Shader来取代原有的前端相关的Shader Stage,并通过驱动在生成的Primitive Shader中加入图元剔除功能,使整个前端利用率大幅上涨。但遗憾的是,因为硬件bug,这个功能没能实现。实际在Vega早期的驱动中,已经实现了部分传统Shader Stage的取代。后期因为NGG的bug所以Shader Stage的驱动也被放弃。RDNA出世之后,NGG终于得到实现,大部分前端相关的Shader Stage都被新的Surface Shader和Primitive Shader所取代,前端性能表现大幅提升,但Vertex Shader依然保持原样。RDNA2中,AMD的前端依然被限制在4个,但是通过RGP观察发现,在RDNA2中几乎全部Shader Stage包括Vertex Shader都被Surface Shader和Primitive Shader所取代,只在流水线中非常罕见的能简单几条Geometry Shader。RDNA2完成了NGG的完全体进化。DX12U的Amplification Shader和Mesh Shader都被映射在了RDNA2全新的Surface Shader和Primitive Shader身上,完美实现了DX12U的要求的功能。
RDNA2的光栅器和之前不同,现在是每周期输入一个三角形,生成32个像素。之前的光栅器都是每周期输入一个三角形,生成16个像素。Navi21中的4个光栅器可以生成128个像素,可以在Pixel Shader Stage中喂饱80CU,也可以对应Navi21中的128个Color ROP,效率不错。当然缺点也是有的,对于无法覆盖32个像素的小三角形,这种设计就比较恼火了,比如一个覆盖4像素的三角形,在生成16像素的光栅器中,可以达到1/4的效率,而在RDNA2中就只有1/8了。
RDNA的TMU,因为L1带宽增加了一倍的关系,64bit的Texel吞吐率相较之前的GCN增加了一倍。在RDNA2中,TMU则为增加了对DX12U新功能,sampler feedback的支持。sampler feedback可以让纹理操作更加的流水化。按照AMD的说法,可以优化显存的足迹,可以对限定层级的mipmap进行纹理过滤,还能异步更新纹理数据。除开可以让纹理操作更加的流水化,sampler feedback还能支持texture space rendering,一种次世代的渲染方法,可以以纹理坐标系为基础直接进行渲染,然后使用传统纹理映射步骤融合到正常的渲染过程中。这个可以针对纹理玩出很多花来,这里先不赘述(稿子赶不完了)。
Render Backend这次改名成了Render Backend+,最大的改变在于RB中的Color ROP数量翻倍,同样的16个RB,现在有128个Color ROP,256个Z/Stencil ROP,而5700XT中为64个Color ROP和256个Z/Stencil ROP。
DX12U的另一个功能是VRS,可变比例渲染,简而言之就是,可以让程序员控制,在某些不明显影响画面质量的地方,降低分辨率。在传统流水线中,都会提供硬件反锯齿功能,实现方法就是对像素进行超采样,然后混合各个采样点的颜色,得出像素更加准确的颜色。这也是VRS出现的基础,VRS实际上就是AA功能的逆向应用,AA是一个像素采集多个样本,而VRS是多个像素只采集一个样本。像素减少极大的降低了很多部件的压力,从而可以实现不错的性能提升。RDNA2也为这一功能提供了支持。我们这里可以看一下3Dmark的VRS测试结果:

6800XT从VRS获益的百分比大约87%,3080大约57%,可能是因为3080的计算性能过剩的原因。
物理层面
从RDNA1开始,AMD的GPU团队就借用了CPU设计团队的人才来优化物理层面的设计。这使得RDNA1的频率追上并超过了同期Nvidia显卡的频率,并大幅拉近了能耗比差距。在RDNA2中,频率优势得到了进一步的优化。RDNA2依然使用台积电的N7P制程,但不同的是这次在显卡上使用了高性能库。在逻辑单元的设计上也更加的流水化。最终使频率提升到了2.5Ghz+。能耗方面,通过更加普遍更加细粒度的时钟关断和供电关断,让任何单元在闲置的时候都尽可能的少占用功耗。特别的,这次时钟树也被分割成小块,并且也可以被时钟关断。所以这代我们可以在GPUZ中看到核心和显存在没有负载的时候,可以降低到0Mhz。
架构部分因为时间匆忙,终于在公交车上用手机打字完成了,里面肯定很多纰漏,我会在之后慢慢修正、补充,欢迎并谢谢大家观看。