
本人有幸拿到了蓝宝石的7900XT超白金送测,这里为大家带来RDNA3架构的解析和实际测评。




架构部分
CU
RDNA3在CU部分做了极大的改进,所以把CU部分摆到了第一位。
RDNA3的CU整体框架与RDNA2差别不大。L1I总计32KiB大小,指令拾取单元从L1I取指之后会将指令放入两组指令缓冲,两组指令缓冲分别对应着两组SIMD。每组指令缓冲最多可以存放对应16个硬件线程的指令,每条硬件线程都有自己对应的程序计数器。之后缓冲中的指令由线程调度器通过一系列条件(比如数据缓存的命中率,或者标量ALU的指令控制),挑选出最多7条硬件线程的指令送往下面的执行单元。执行单元有两个SIMD单元,两个标量ALU,一个访存/纹理/光追加速单元,一个LDS,一个GDS/Export单元,这些单元可以同步执行来自7个不同硬件线程的指令,也就是说可以实现最多7发射,但对于一个硬件线程来说依然是单发射。

RDNA3相对于前代最大的不同点在于它的SIMD。一直以来AMD这边所说的SIMD其实不是一个单独的SIMD,而是多个不同类型SIMD的合集,类似于Nvidia现在架构中Math Dispatch下面挂的那一堆SIMD。


在RDNA3的SIMD中,新添加了一个FP32 SIMD32,和两个用于AI加速的SIMD64(分别对应Dot2和Dot4)。RDNA系列的前两代中,SIMD只有一个发射端,在Wave32模式下,可以刚好喂饱其中的其下的一个FP32 SIMD32,在Wave64模式下,FP32 SIMD32需要两周期才能完成一条FP32 SIMD指令。
而RDNA3中,因为新加了一组FP32 SIMD32,单发射的发射端如果使用正常的指令,在Wave32模式下只能喂饱其中一组,所以AMD为RDNA3的Wave32模式添加了VOPD指令格式。该指令格式可以将两条指令打包成为一条VOPD格式指令,这样就能通过仅有的一个发射端,同时驱动两个FP32 SIMD32。VOPD在性质上来说就类似于VLIW指令,但它的编码格式没有增加最大指令长度,也没有增加指令延迟,例如VOPD的双FMA指令延迟和正常FMA指令一致为5周期。VOPD指令虽然能解决驱动两个FP32 SIMD32的问题,但它也有极多的限制,它需要编译器或者汇编程序员来处理数据依赖,两条指令的常量、立即数和标量寄存器只能使用同一个,目标寄存器需要是一个奇数号一个偶数号,源寄存器需要使用不同的Bank,甚至支持的指令也是有限的,第一个SIMD支持16条指令,第二个SIMD只支持13条。如此多的限制下,VOPD驱动的第二组FP32 SIMD32可能仅仅是一个锦上添花的东西。
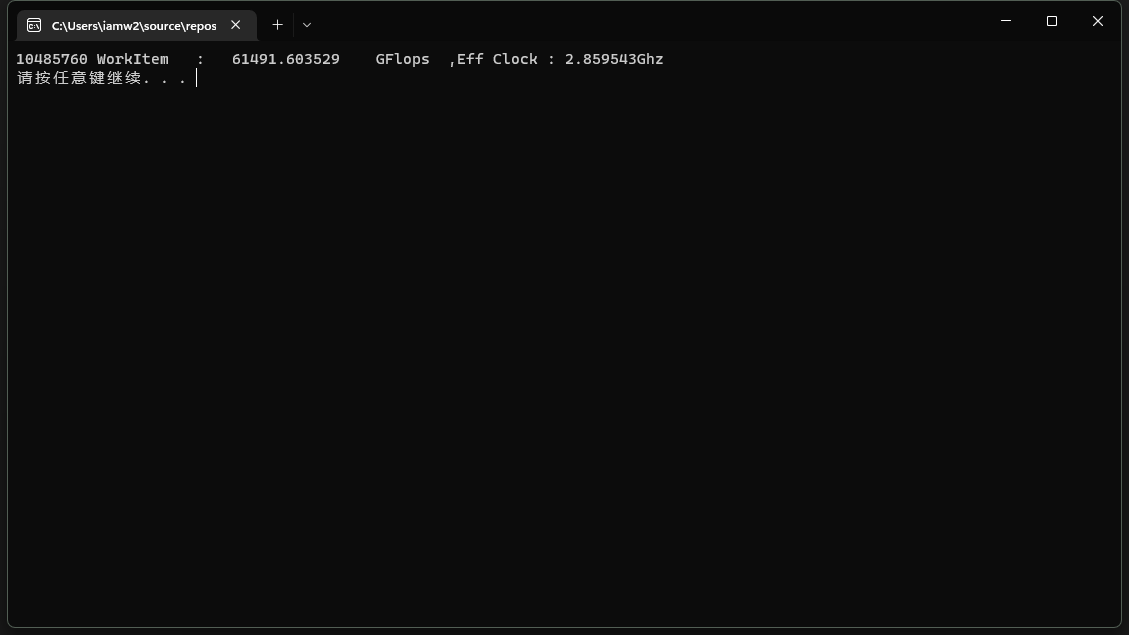
实际测试中,利用我自己写的OpenCL测试程序测得Wave32模式下,VOPD的两条指令中,最多在各自使用一个源向量寄存器时,在我手上这块7900XT 超白金上可以达到61.5TFlops的浮点吞吐率,有效频率大约2.86Ghz。使用其他任意格式均会导致吞吐率下降到一半水平。
在Wave64模式下,和AMD PPT上写的不同,RDNA3采用单发射端交替发射的模式喂饱两个SIMD32。这样,对于需要吞吐率的应用,在Wave64下可以较为轻松的利用起增加的SIMD,限制上少很多,延迟上也与上代保持一致,为7个时钟周期。不过Wave64模式下,寄存器压力较大,所以前一代中AMD都只在相对可能更简单的Pixel Shader中使用Wave64模式,RDNA3中AMD将寄存器堆容量增加了50%,L0也增加了一倍,应该就是为了应对Wave64模式下,寄存器压力较大的问题。
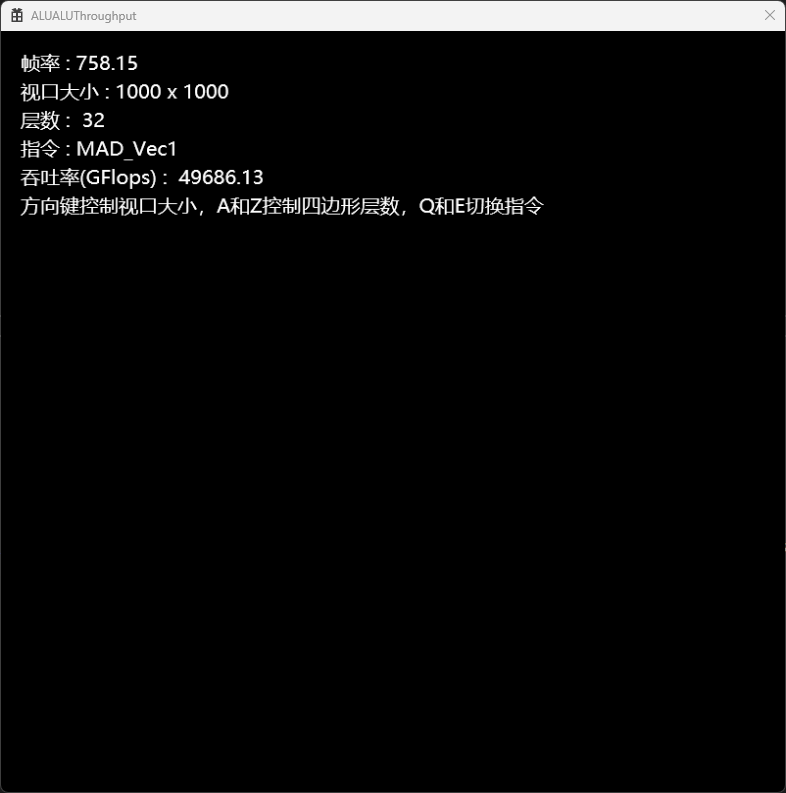
通过PIX Profile D3D程序可以得知,Direct3D下所有Shader都已经采用Wave64模式。所以使用我自己写的D3D12程序可以测得,无论何种格式的FMA指令,在Wave64模式下都至多只能获得5/6的峰值吞吐率,而常用的格式下甚至更低。稍微评价一下RDNA3这次增加一组SIMD的做法,大概就是硬塞了一组进去的感觉,寄存器方面完全没有做任何准备,比较令人失望。
接下来说下CU新增的WMMA,也就是矩阵加速器,从LLVM的代码可以看到AMD的WMMA指令,除了名字和Nvidia Tensor Core的WMMA指令一样以外,内容也差不多。回到硬件本身,AMD的Dot2 WMMA指令支持FP16、BF16和INT8,Dot4则支持INT4,宽度都为64。用FP16来算的话,DOT2等效于两个乘法操作加上两个加法,也就是每周期256个浮点操作,从单CU的性能上来看,大约和Nvidia图灵架构的差不多,对于一般AI方面的应用而言,其实是非常足够了,而且考虑到AMD之后会引入赛灵思的AIE,这种规模完全合情合理。
光追加速器方面,AMD主要增加了对Ray Flags的硬件支持。Ray Flags是DXR的Shader中通过TraceRay内联函数传递给求交之后的处理函数的光线特性覆盖标志。通过这个标志可以实现一系列高级操作来减轻复杂光追的开销。LDS也新增了一条指令,取代了以前需要由多条ALU和LDS指令配合完成的复杂操作,让每个遍历操作中减少了50条指令,降低了4倍的L0总线开销。同时增加的1.5倍寄存器,也让光追Shader的寄存器压力降低很多,实现了更高的计算单元的利用率。这块我不熟,就不测了。
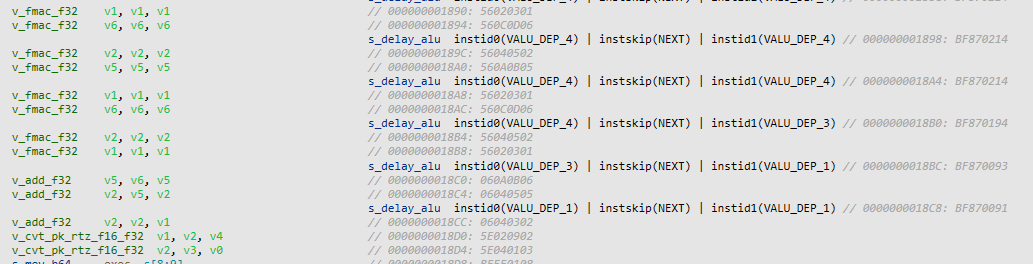
调度上,RDNA3为SALU增加了s_delay_alu指令用于提示调度器接下来的指令相关性以及延迟等信息,改善了线程切换的准确性提升了CU的性能和功耗表现。这里多讲一点,GCN的调度模式是每周期都切换线程,所以GCN没办法使用寄存器缓存,每次计算都需要重新到主寄存器堆取数据。主寄存器堆很大,工作功耗会很高。而Navi开始加入了s_clause指令用于提示调度器接下来的指令可以不切换的连续执行,这样前后指令需要的数据可以被放在一块很小的操作数缓存中,写出的结果也可以通过结果缓存让后面的指令使用,大大降低了寄存器访问功耗,这也是Navi与GCN能耗比差距巨大的根本原因。同时通过软件辅助的调度器本身功耗也可以更小一些。
缓存
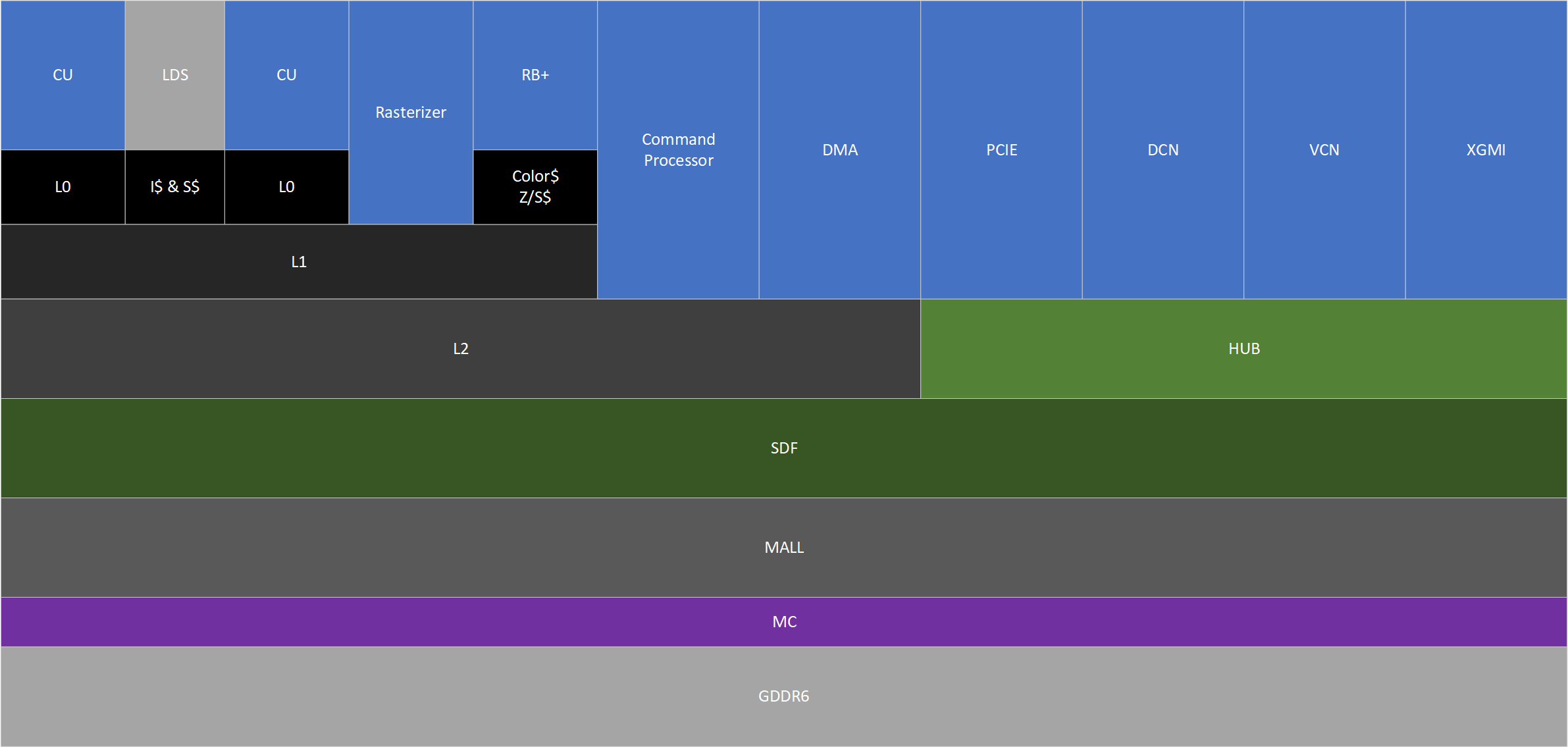
RDNA3的缓存结构与RDNA2保持一致,但在容量上有了一些变化。
首先是L0缓存的大小翻倍,来到了32KiB。AMD和Nvidia的CU私有缓存容量差异很大,这导致了很多优化方向上的差异,在上一代RDNA2中L0仅有16KiB,而Nvidia从安培开始增加到了64KiB,AMD也增大L0可以让这种差异减少。
然后是AMD独特的SE内共享的L1缓存,AMD认为L1缓存作为SE内的数据交换中心可以极大的降低互联的复杂性和数据交换的功耗。通过AMD的RGP工具观察多个游戏L1命中率可以发现128KiB确实有点捉襟见肘了,很多时候只有百分之十几的命中率。所以RDNA3上AMD也直接将它翻倍了。
L2没有什么亮点,配合位宽增加而增加。
Infinity Cache就很有意思了,AMD将他的容量减少了一些,从128MiB降低到了96MiB,但双向总带宽增加到了5.4TiB/s,同时在指令编码中的DLC位改为了对于IFC的控制位,方便程序员或驱动将不需要缓存的数据绕过IFC,AMD表示这样可以将有效带宽拉到3TiB/s以上,这个提升还是非常可观的。
实际测试中,我只测了单向带宽,缓存内能达到2.5TiB/s。
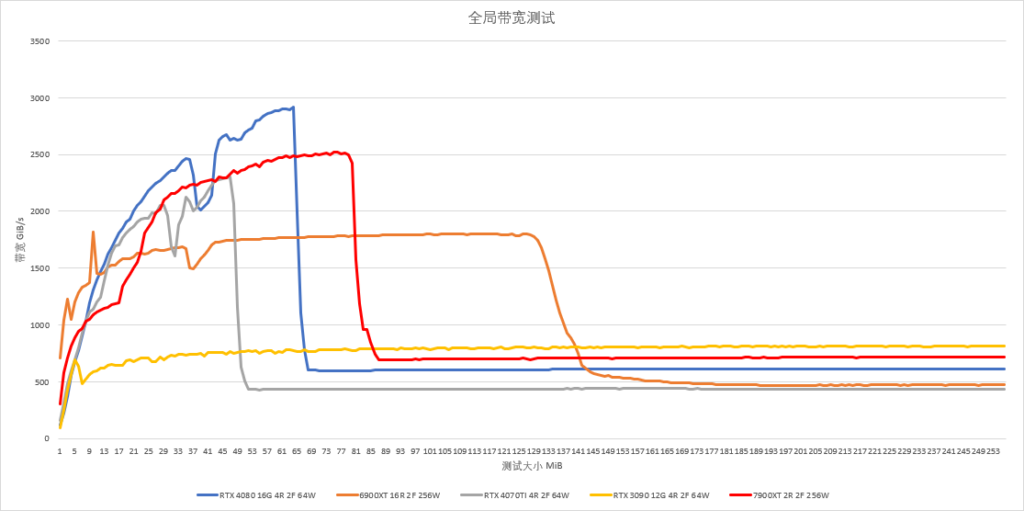
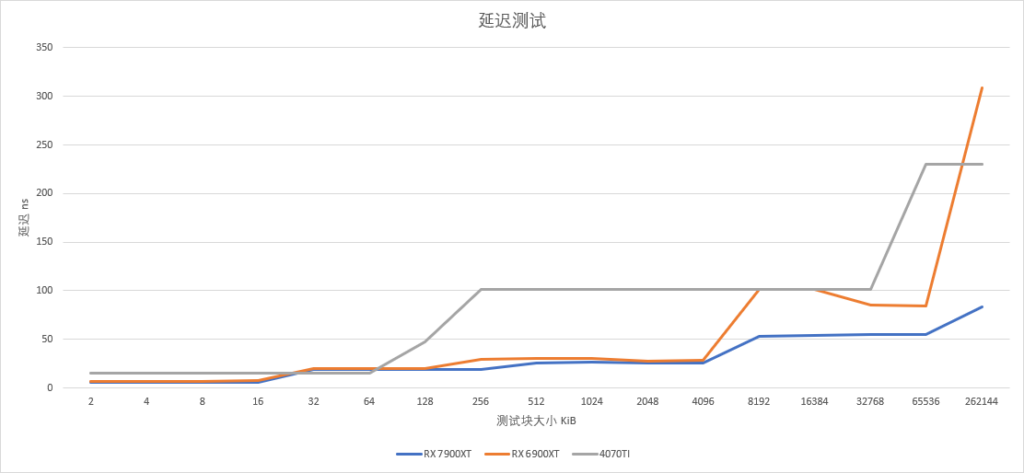
顺便测了点延迟,RDNA3相对于RDNA2,L0、L1、L2延迟周期基本保持一致,但IFC的延迟从85ns左右降低到了55ns,除开AMD PPT上提到的频率提升之外,本身访问特性上可能也有了很大的改进。
图形专用硬件
MDIA
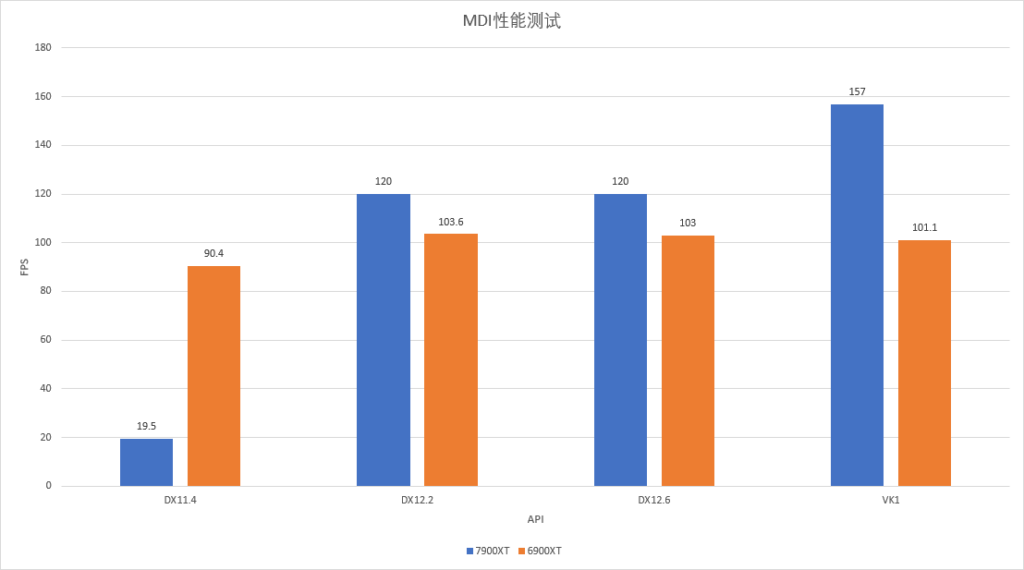
Multi Draw Indirect是图形API中的功能,简单的理解就是可以将多个DrawCall合并为一个,从而减小CPU开销。RDNA3加入的Multi Draw Indirect Accelerator可以在GPU处理指令数据,从而让MDI的性能更好。
实测使用Tellusim的DrawMesh测试来进行,在DX12下79XT大约获得了20%的提升,Vulkan下更好一些,有50+%。但DX11不知道因为什么原因,反而有了大幅的退步,难以理解。
硬件Primitive Culling
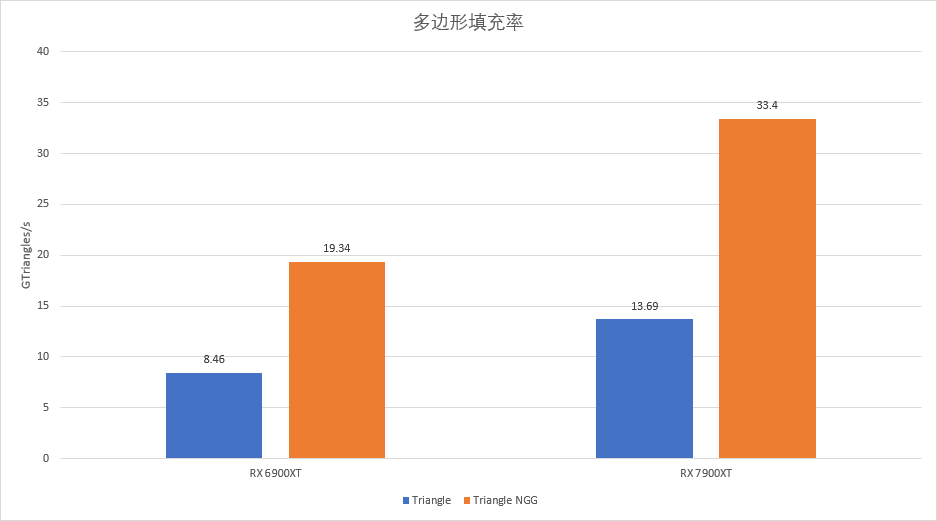
在RDNA2中NGG生成的Primitive Shader最后,会附加一段用于Primitive Culling的Shader代码,对于Navi21来说可以实现最高2倍的Culling后Primitive 吞吐率,Navi22则是4倍。但利用Shader来实现,始终是有额外开销的。RDNA3中AMD使用硬件来实现这个效果,为RDNA3中本来寄存器压力就很大的Primitive Shader减少了一些负担。
实际测试中,我们可以在69XT和79XT上都看到超过两倍的提升,原因是在非NGG状态下,所有芯片都无法达到理论值的多边形吞吐,但在NGG生效之后,可以几乎完美达到理论吞吐率。
有意思的RDNA的硬件Primitive Culling不止减少了Primitive Shader的开销,顺便还降低了功耗。NGG生效非生效状态下,69XT功耗差距有将近30W,而79XT仅仅0.9w。
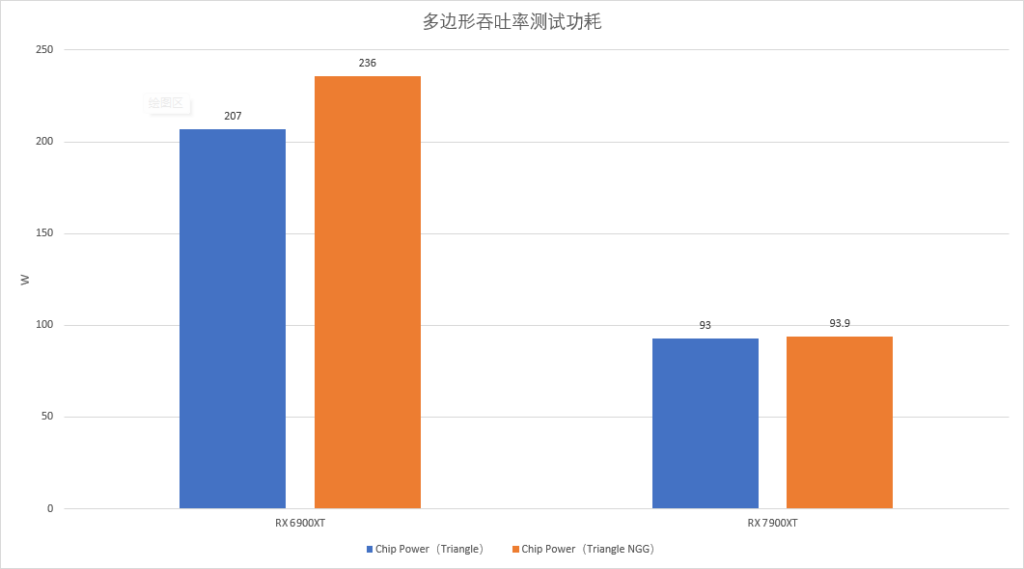
随机顺序非透明导出
GPU在Pixel Shader完成后,像素会进入ROP进行Blend步骤,有透明度的像素的Blend顺序会影响最终色彩,所以AMD之前设置了一个重排序缓冲区(没错就是类似CPU上那个重排序缓冲区)来保证像素输出顺序的正确性。但是对于非透明或者非重叠的像素来说,这个步骤显然是多余的。只需要一个简单滑动缓冲区就可以搞定,不用保存巨量的结果。对于Pixel Shader来说效率也可以得到改善。
物理设计
频率
之前传言说RDNA3的设计频率极高,确实如此,RDNA3的设计目标频率在3Ghz,但为了更佳的能耗比,AMD把频率压得比较低。我手上这块7900XT超白金的最大功耗只有400W,电压最高只有1.1v,不足以让我摸到RDNA3的频率上限,但我大致测试了一下。和前面一样,使用自制的OpenCL FP32吞吐率测试程序给CU压力,然后往上拉频率,最终在3.5Ghz、1.1v、 400w下达成了75TFlops的浮点吞吐率。
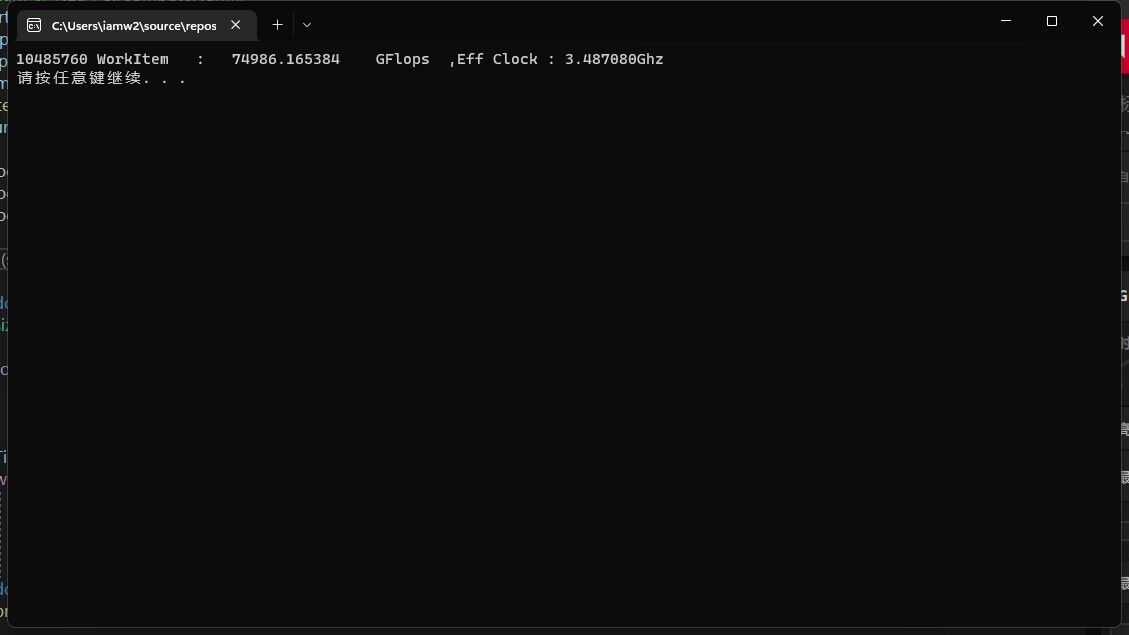
并且我简单的测试了频率/功耗曲线:
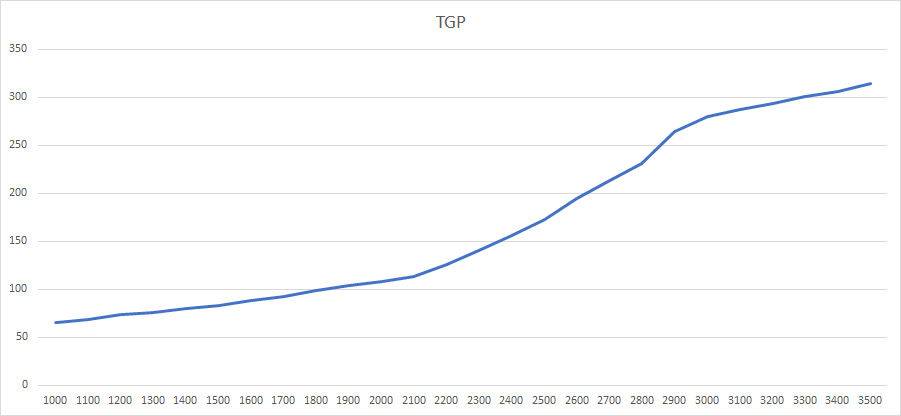
在2.8Ghz附近电压就已经到了1.1v,不再上升,所以之后的功耗上涨非常平缓,直到3.5Ghz。在面板中将频率继续往上拉的话,会卡死,即便这时候没有负载。这应该不是RDNA3架构的上限。
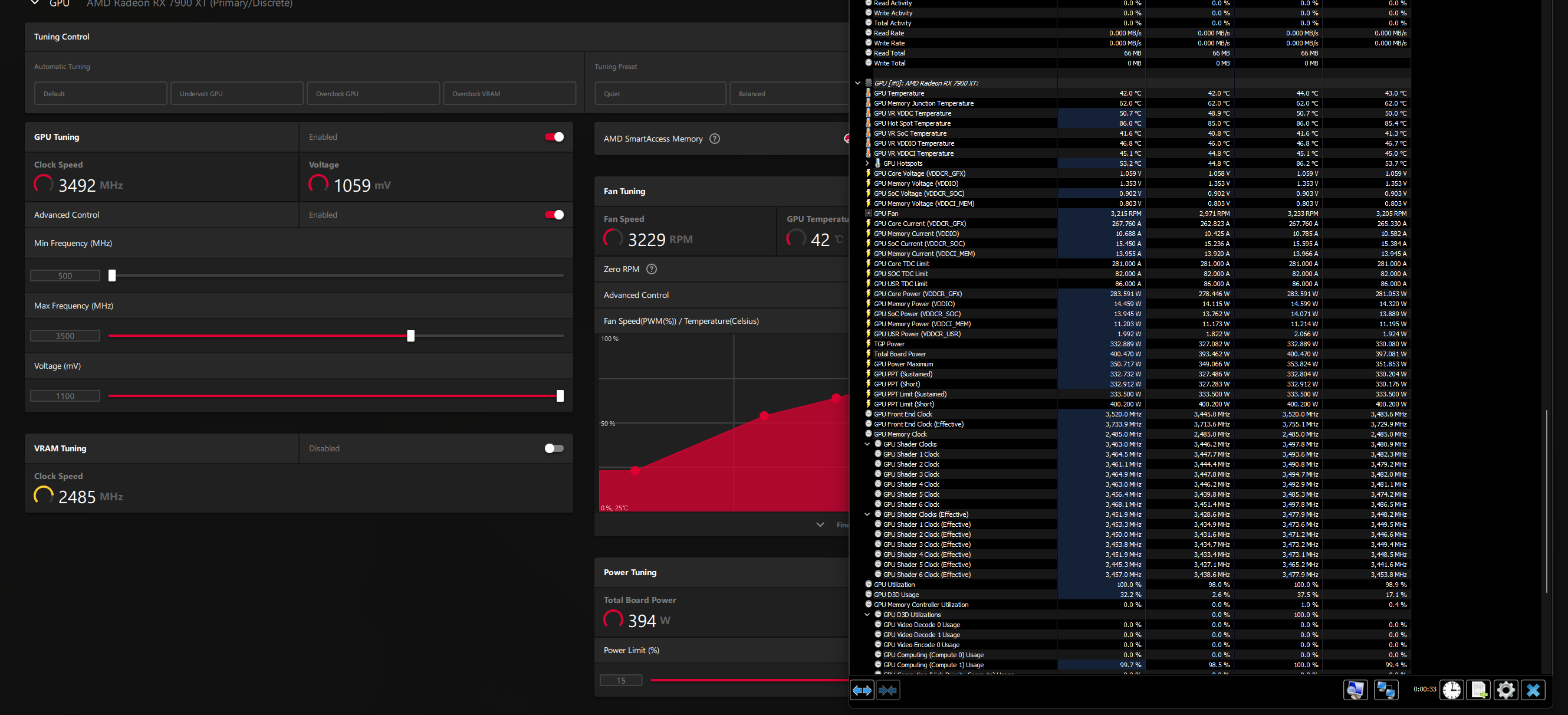
需要注意的是,当前仅仅是CU有压力,而图形流水线中还有其他部分。实际图形负载的话,因为TDP,TDC,和电压的三方限制,最多在游戏中可以看到3.25GHz左右。如下图所示的情况为电压限制。
AMD之前提到RDNA3将任务前端频率与Shader频率分开了,实际测试中确实如此,任务前端频率总是比Shader频率高0.2Ghz左右,Shader运行在3.5Ghz的时候,任务前端已经达到了3.7+Ghz。AMD将任务前端分频原因我猜测可能与它现在需要负责6个SE的任务调度有关,更多的SE需要更强的性能。
除开任务前端分频,实际6个SE的频率也已经是分开的了,最显而易见的好处是,在低负载时,可以将任务全部放在一个SE,而别的SE轻易通过时钟关断等手段来降低动态功耗。同时我认为这与AMD之后将要实现的更细的Chiplet设计有关,可能以后就是任务前端一个Chiplet,每个SE一个Chiplet。
Chiplet
说到Chiplet,Navi31将Infinity Cache和显存控制器以及PHY,这几个性能或面积对于工艺提升不敏感的器件做到了6nm的小芯片内存缓存晶片(Memory Cache Die)中,其余需要高性能高密度的部分则使用5nm工艺做成图形计算晶片(Graphic Compute Die)。最终一片图形计算晶片与六片内存缓存晶片通过高级封装互联在一起成为Navi31芯片。这样让昂贵的5nm用到了刀尖上,最终为玩家带来了实惠的价格。
实测
首发测试只有两张卡的成绩,测试平台如下:
| CPU | Ryzen R9 7950X | Ryzen R9 7950X |
| 内存 | GSkill DDR5 6000 16G * 2 | GSkill DDR5 6000 16G * 2 |
| 主板 | MEG X670E ACE | MEG X670E ACE |
| 显卡 | 蓝宝石RX 7900 XT超白金OC | AMD RX 6900XT |
| 硬盘 | 致态 TiPLUS 5000 2T | 致态 TiPLUS 5000 2T |
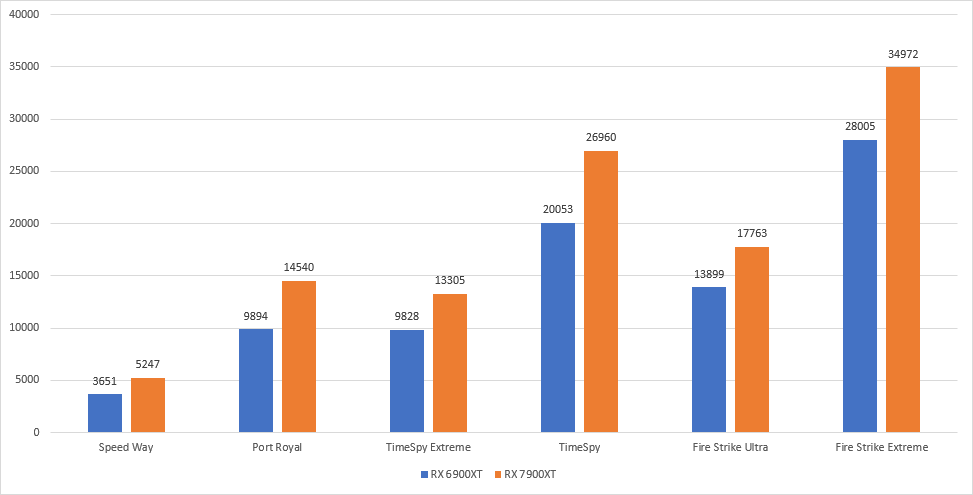
跑分测试
游戏测试

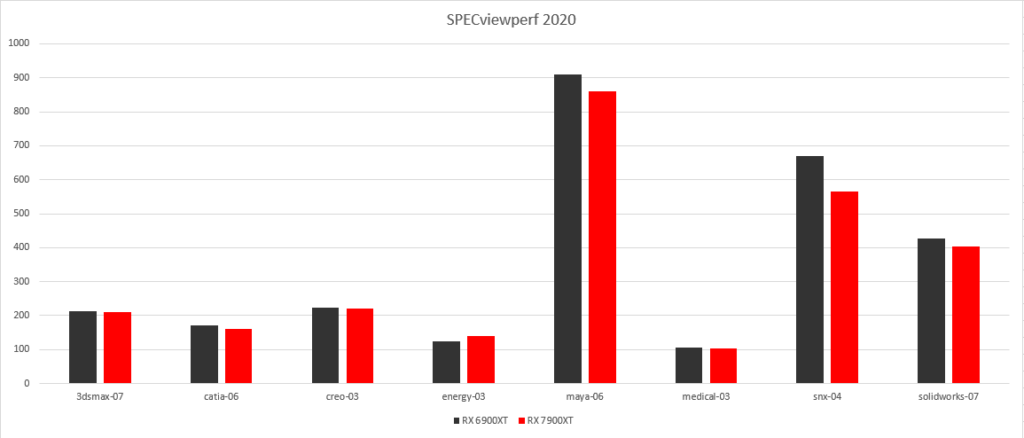
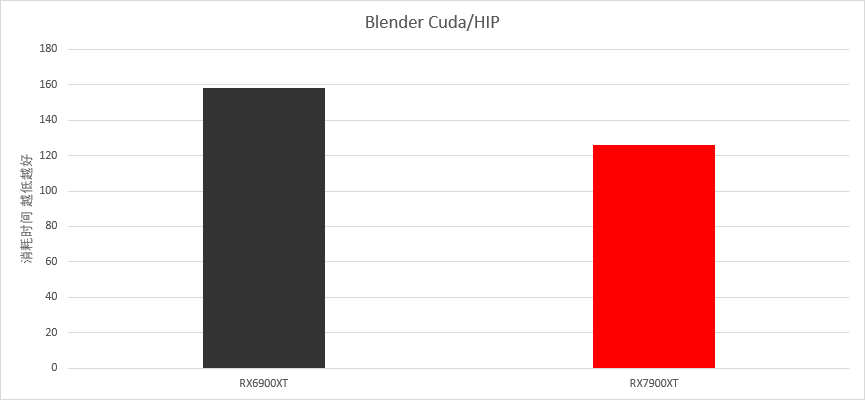
专业软件
总结
从成功的RDNA2架构发布至今,时隔两年AMD迎来一次激进但不算完美的架构更新,潜力巨大,任然需要在架构上的进一步完善。实际产品上,7900XT在游戏方面带来了相对于上代26%的性能提升,通过合理的价格定位,让这款显卡的购买价值依然优秀。