RDNA3架构的RX7000系列显卡在本月3号已经发布了,前几天AMD又举办了一个线上的RDNA3 GPU的技术分享日,我有幸受邀参加了。过来给吧友们分享一些会上两位重量级人物的讲解:

AMD 高级副总裁 大中华区总裁

AMD Radeon 技术事业部工程研发高级副总裁
大会开篇由潘总致辞,表达了对过往RDNA2架构显卡的认可,以及对全新RDNA3架构的期待:
2020年,基于RDNA 2架构的AMD Radeon RX 6000系列显卡一经亮相便艳惊四座,为PC游戏体验树立行业新标杆。再加上锐龙处理器的助阵,和更多前沿技术和功能的支持,又一次为玩家提供了整体台式平台的巨大升级。
AMD一直致力于将优异的AMD Radeon显卡带给发烧友和游戏市场,用不断精进的图形能力令用户收获极致体验,用一款又一款的优秀产品引领行业进入一个全新高性能时代。
对于全新一代AMD Radeon RX 7000系列台式显卡与RDNA 3架构,充满了期待与憧憬。正如全新AMD Radeon RX 7000系列台式显卡一样,AMD将一如既往的为广大玩家和行业带来优秀的产品、满足时代的需求,请大家拭目以待。
之后大卫王则表达了AMD为游戏市场所做努力的肯定:
在AMD我们的愿景是为了全世界数十亿的游戏玩家能够提供更卓越的游戏体验,这包括我们AMD的锐龙处理器、Radeon显卡、云游戏服务,以及新一代的游戏机,包括PS5、Xbox跟Valve Steam Deck,而且在这个最新的特斯拉电动车当中,能够把游戏体验带进现在的汽车市场。
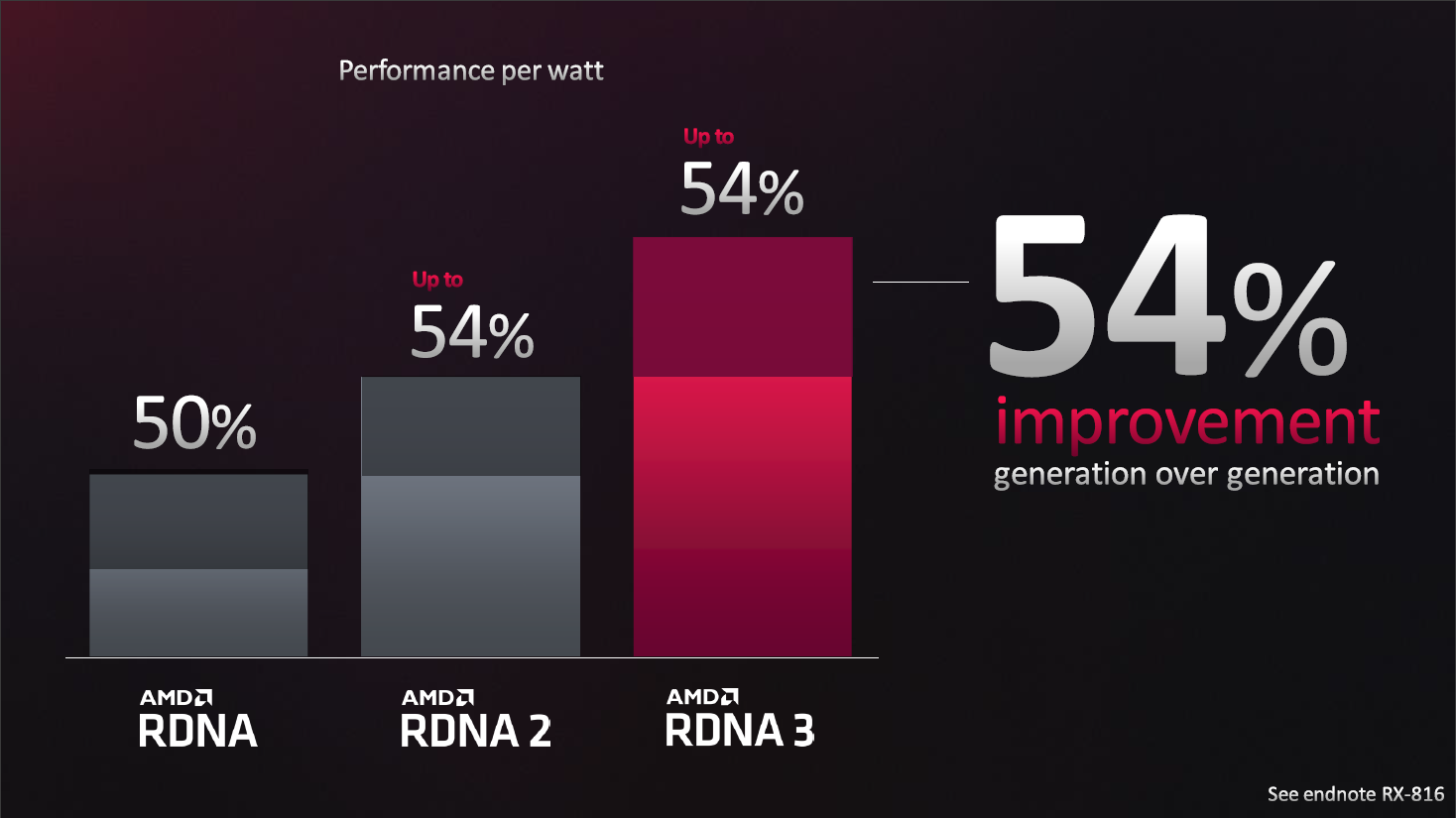
对RDNA3架构再次突破既定目标,大卫王很是开心:
我很高兴能够告诉诸位,我们再次地超越了我们原来所定的目标,RNDA 3实现了54%的每瓦性能的提升,使得我们在三代,从当初的Vega到RDNA,从RDNA到RDNA 2,到RDNA 3,在三代之间实现了超过350%的累计的提升。
随后便是大卫王对于RDNA3架构的详细讲解,我就来给大家解读一下有哪些值得看的地方:
新的RDNA3架构的首款GPU,Navi31采用了业界领先的Chiplet架构,将Infinity Cache和显存控制器以及PHY,这几个性能或面积对于工艺提升不敏感的器件做到了6nm的小芯片内存缓存晶片(Memory Cache Die)中,其余需要高性能高密度的部分则使用5nm工艺做成图形计算晶片(Graphic Compute Die)。最终一片图形计算晶片与六片内存缓存晶片通过高级封装互联在一起成为Navi31芯片。

图形计算晶片与内存缓存晶片总共承载了580亿晶体管。

每个内存缓存晶片上有一个64Bit的GDDR6 PHY与控制器,与上代一样,第二代Infinity Cache作为一种内存侧缓存与GDDR6控制器绑定在一起,最后通过一个高密度的PHY链接到GCD。
Navi31上,内存缓存晶片总计可以提供5.3TiB/s的峰值数据带宽,是上一代单晶片Navi21的2.7倍,算下来一片内存缓存晶片就能提供将近900GiB/s的带宽,这就是高级封装威力。

图形计算晶片包含了全新的图新核心、全新的显示引擎、全新的双多媒体引擎、PCIE PHY和控制器。

针对游戏优化的计算单元。计算单元因为逻辑部分晶体管占比较多,所以充分享受到制程提升带来的密度红利,每平方毫米晶体管是上代的1.65倍。
从RDNA1到RDNA2的GC都属于GFX1000系列,所以计算单元变化不大,而RDNA3的GC版本更新到了GFX1100系列,计算单元几乎进行了全方位的改动。
其中最重要的一个就是计算单元中的SIMD可以实现部分指令的双发射。在Wave32模式下,通过RDNA3全新的VOPD指令编码格式,可以将总共十七条不同的指令中的两条打包为一条指令发射给一个SIMD同时执行,实现双倍的指令吞吐率。
为了配合双倍的吞吐率,向量寄存器的容量也提升到了1.5倍(为什么不是双倍,因为VOPD编码限制了两条指令需要有一些的同样的寄存器),L0数据缓存和LDS则是容量翻倍。


与此同时,RDNA3的计算单元也引入了两个独立的AI加速器,通过WMMA指令调用为RDNA3提供AI加速。BF16格式下性能为上代6900 XT的2.7倍。

计算单元的光追加速器也更新到了第二代。通过新的指令和对光线包围盒排序与遍历的优化实现了50%的性能提升。

解绑的时钟,这代AMD将Shader频率和前端(Command Processor)部分的频率分在了不同的时钟域,大卫王解释说Shader性能目前已经足够,瓶颈在于任务分发以及命令处理上,单独提高前端的频率,并且让计算单元工作在较低的频率上,可以实现更高的整体效率,最高可以节约25%的电力消耗。

最终在计算性能上,Navi31达到了61 TFlops的FP32吞吐率,而上代只有23 TFLops。

图形和计算部分说完,来看看显示引擎。这代显示引擎被AMD称为AMD Radiance DisplayTM engine。主要亮点是支持Display PortTM 2.1这个尚未诞生的标准,可以说是真正意义上战未来的技术了。DP 2.1可以支持到8K分辨率下165的刷新率,4K分辨率下480的刷新率,让现在分辨率与刷新率不可兼得的尴尬局面被彻底打破。

接下来看看新的双多媒体引擎,在RDNA2中,编解码速度与质量表现都不算出色。这代则针对性的进行了提升。针对串流任务,这代两个多媒体引擎可以同时支持AVC和HEVC两种格式下的编码和解码任务。而上代中为人诟病的AV1编码下只有8k24的AV1解码速度也得到了改善,来到了8K60。同时也跟上时代的潮流提供了AV1编码的支持。更有意思的是它提供了AI辅助的视频编码技术,虽然细节还不清楚,但对于质量方面肯定有不少提升。

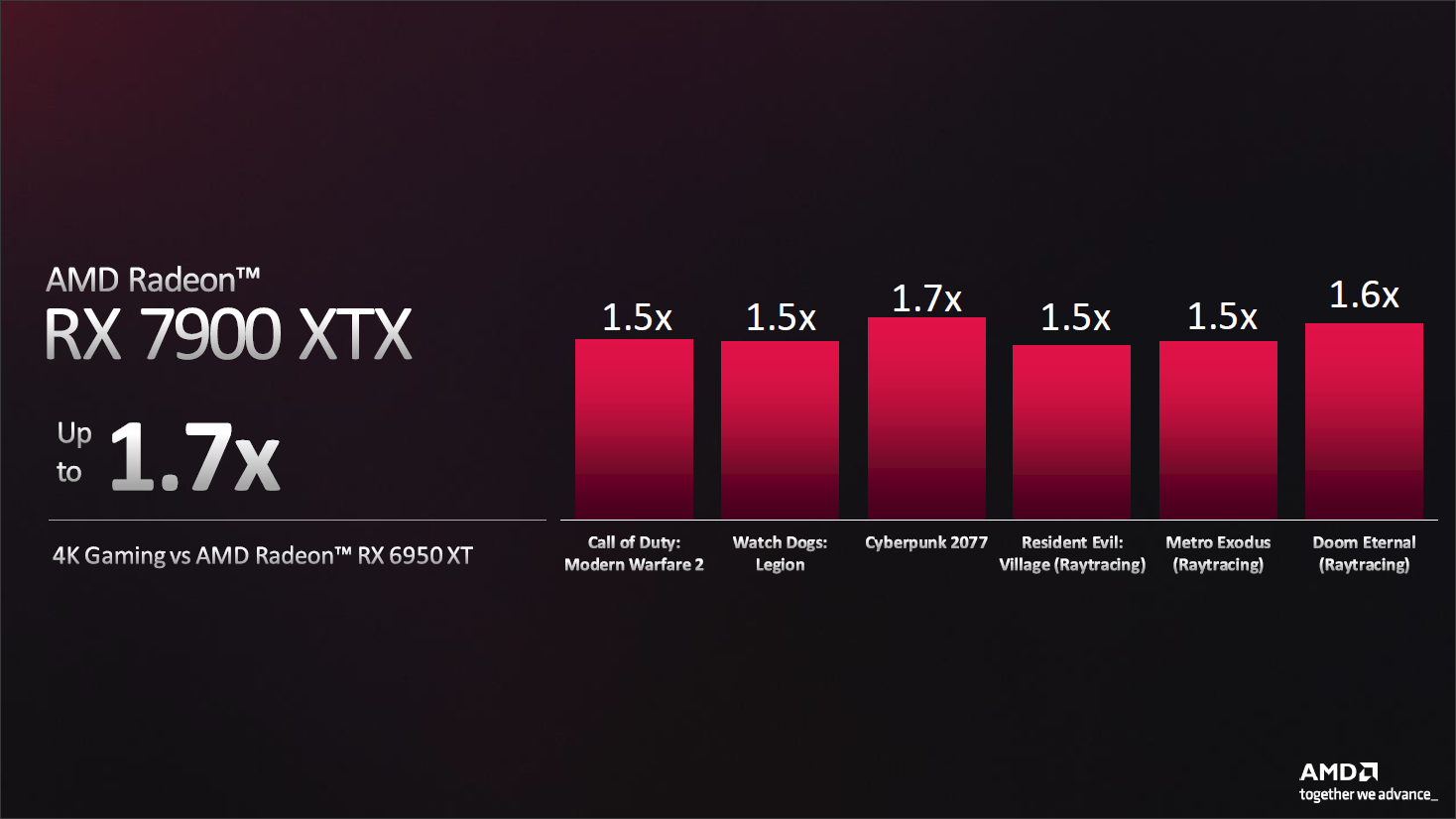
结合上面RDNA3的特性,最终AMD首批发布的就是7900 XTX和7900 XT:


其中7900 XTX,在4K下可以实现最高1.7倍于6950 XT的实际游戏性能提升。
最重要的是,玩家可以平滑升级,没有高达450w TBP的功耗,也就不需要巨大的体积和不稳定的新供电接口。2.5槽,不浪费主板接口,355W的TBP,仅需双6+2 Pin供电,安全可靠。

除开硬件的改进,AMD也将在软件进行升级,首先是最近的FSR 2.2,前天已经在Forza Horizon 5上更新了,质量对比,我会在稍晚点放出来。

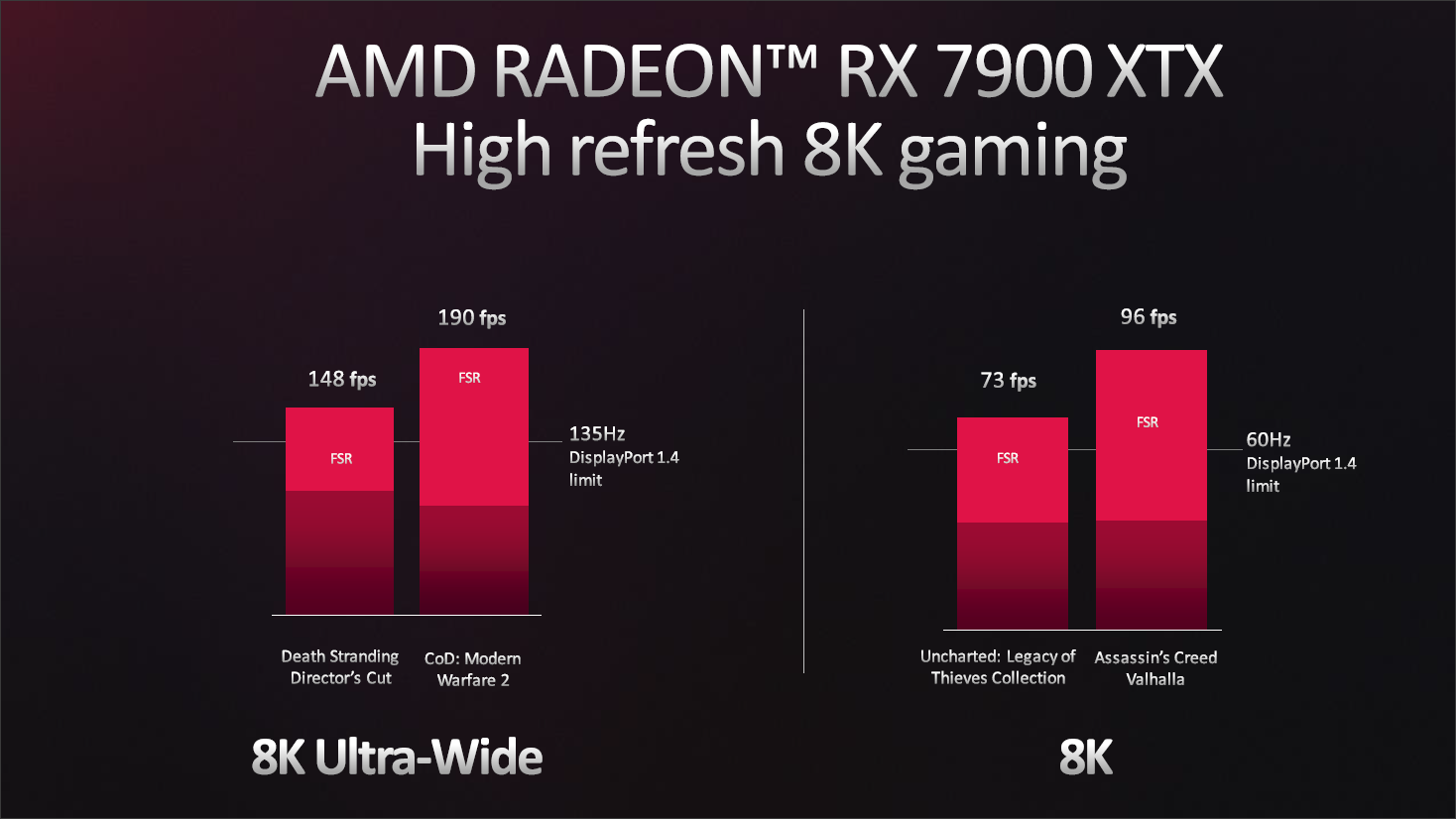
在8K下,使用FSR配合DP 2.1可以实现高分辨率同时高刷新率的极致游戏体验。
明年AMD还将推出FSR3。AMD曾经在视频回放上有个成名绝技Fluid Motion,而FSR3则是通过全新的Fluid Motion Frame插帧的方法配合FSR2,可以实现最高两倍于FSR2的帧率。

最后问答部分,有个大家都关注的问题,就是7900系列供货是否充足?
AMD大中华区渠道销售副总裁梅晨和AMD大中华区显卡渠道销售总监廖宜邦先生表示,AMD内部夜以继日的在准备供货,他认为发布时供货应该是充足的,除非玩家太过于追捧这款显卡。