Intel在上月末终于发布了它近年来的第一张正式零售的独立显卡,Arc A380。本人有幸在消息灵通的六副总的及时通知下,以冤大头价拿下了世界第一张零售的Arc A380。经过一周多的把玩之后为大家带来这篇测试。




Xe-HPG架构
Arc A380是炼金术士(Alchemist)系列或者说DG2系列的低端显卡之一。炼金术士系列是Intel新世代独显中的第一个系列,后续还有战斗法师(Battlemage),天人(Celestial),德鲁伊(Druid)。Alchemist系列的架构代号是Xe-HPG,按Gen的代号来看是Gen12,具体版本号是Gen 12.71。与它同代的架构还有核显和DG1独显使用的Xe-LP/Gen 12.1,Arctic Sound数据中心显卡使用的Xe-HP/Gen 12.5(据三哥的说法,已经取消发布,只有Intel自家的OneAPI的开发云上部署了),Ponte Vecchio数据中心显卡使用的Xe-HPC/Gen 12.72。我们今天当然主要关注Arc A380的Xe-HPG。
Xe Vector Engine

Xe-HPG中最小的独立处理单元为Xe Vector Engine(XVE),曾今叫做EU,它的存在类似于Nvidia架构中SM里面的SubCore。
Xe-HPG的每个XVE同时最多可以维持8条硬件线程(Wave,Xe-LP为7条)。8条硬件线程共享XVE中的资源,和大多数GPU一样,执行资源通过分时共享,储存类的资源则是容量共享。通过这种方式,可以让它掩盖掉一些比如访存之类的长周期的操作延迟。Intel的Wave对应的数据宽度是灵活可变的,宽度可以为2、4、8、16、32。Wave的指令存放在他们各自对应的指令缓冲中,解码之后,通过记分牌调度决定是否发射。
计算部分总计有四个发射端,分别对应着浮点,整数,1超越函数和矩阵运算引擎。浮点和整数部分的执行单元为宽度为8的SIMD,超越函数是宽度为2的SIMD,矩阵运算单元则是1024bit。XVE比较特别的是,相邻的两个XVE可以共享调度单元,通过拼接的方式来将两个SIMD8组合成一个SIMD16。这样的两个EU被称为Dual EU。虽然听起来像是Dual CU的感觉,但完全不是一个概念的东西。DG2的执行单元的宽度与AMD和Nvidia的比要窄很多,而且原生Wave宽度同样也要窄很多,这意味着在相同的计算能力下,DG2在指令方面的开销要大很多,是两家对手的4倍。当然好处也不是没有,对于分支多的任务,比如光追,来说更友好,对于软件线程数少的任务更加友好。但总的来说,对于目前的图形任务,我认为粒度还是过细了。
Xe Core

Xe Core是Xe-HPG架构中一个完整的计算单元,它类似于Nvidia架构中的SM或者AMD架构中的CU/DCU,因为LDS或者叫SLM被安排在这一级,所以它是最小的Work Group处理单元,同一个Work Group只能在同一个Xe Core中运行。
分配到Xe Core的线程指令首先被放在一个96KiB大小的L1i中,然后通过线程调度器分配给下面XVE。Xe Core中的XVE执行单元宽度很窄,所以Xe Core中包含了16个XVE,算下来总计128 Lane的FP32 SIMD,相比之下AMD和Nvidia的DCU和SM都只有4个Subcore,每个32 Lane的FP32 SIMD,总计也是128 Lane。
Subcore访存相关的操作都由Xe Core中的LSU来执行,Work Group中的数据交换则是SLM来负责。Intel的SLM设计与Nvidia的类似,都是L1D和SLM共享容量,可以按一定比例配置。与访存强相关的纹理单元和光追单元也都放在这儿附近。纹理单元每个Xe Core有8个,与目前AMD架构的比例一致,比Nvidia的高一倍。光追方面,按IMG在去年划定的一个光追标准等级,如下图:
AMD目前处于第二级,Nvidia和Intel处于第三级。可以说Intel的架构至少功能上是实现全了。
Slice

更上一级的Slice是一个具有完整图形功能的部件,他的地位类似Nvidia的GPC和AMD的SE,Xe-HPG中Slice的固定功能单元有几何单元,Hierarchical-Z单元,光栅器和渲染后端,以及处理各种Shader的Xe Core。几何部分主要是一些输入组装,图元组装,以及向后传递的Buffer之类的,光栅器则是负责图元的光栅化,每周期可以吞吐一个图元。Hi-Z则是输出层级化的Z Buffer。渲染后端包含了16个Color ROP和32个Z/Stencil ROP,负责色彩与深度/模板的输出。
Arc A380

将两个Slice组合起来,加上任务接收与调度相关的Command Processor,加上显示输出和媒体处理部分,加上4 MiB的L2缓存,加上3个32 Bit的内存控制器,通过Xe Fabric互联起来就是一个Arc A380的核心了。这里列出一下我手上这块的规格:
| 核心频率 | 2450 Mhz |
| 流处理器数量 | 1024 |
| 纹理单元数量 | 64 |
| 光追单元数量 | 8 |
| 计算核心/Xe Core数量 | 8 |
| 光栅器数量 | 2 |
| ROP数量 | 32 |
| 渲染分片/Slice数量 | 2 |
| 总浮点算力(以FMA计) | 5,017.6 GFlops |
| 总纹理采样速率 | 156.8 GTexel/s |
| 总色彩像素填充率 | 78.4 GPixel/s |
| 总深度/模板像素填充率 | 156.8 GPixel/s |
| 总图元填充率 | 4.9 GTri/s |
| 二级缓存大小 | 4 MiB |
| GDDR6 频率 | 15.5 Ghz |
| 总内存带宽 | 186 GiB/s |
| PCIe规格 | x 16@3.0 |
基础指标性能测试
DX12时代,要找到一个合适图形方面的底层测试软件很难,之前流行的大部分理论测试软件都是DX9时代的,由于当时的测试代码已经远远跟不上显卡和API的进化,基本要么因为API支持问题无法运行,要么就因为测试规模太小,无法让显卡满载。所以我在拿到卡之后尽可能的自己写了点代码。
浮点计算能力测试
| 指令 | GFlops |
| MAD/FMA Vec4 | 4904 |
| MAD/FMA Vec1 | 4907 |
| MUL Vec4 | 2476 |
| MUL Vec1 | 2462 |
| ADD Vec4 | 2475 |
| ADD Vec1 | 2460 |
| LOG Vec4 | 618 |
| LOG Vec1 | 619 |
| SIN Vec4 | 621 |
| SIN Vec1 | 622 |
| SQRT Vec4 | 621 |
| SQRT Vec1 | 622 |
| EXP Vec4 | 620 |
| EXP Vec1 | 622 |
不像AMD和Nvidia的架构,DG2的峰值浮点性能不是很容易实现,有极多细节方面的东西会影响它的吞吐率,最终费劲心思我也只达成了4907 GFlops,距离理论值5017.6 GFlops还有一些距离,SIMD8的指令几乎都是如此,我一度怀疑是SIMD8的指令延迟过长引起的,但仔细一算,实测结果又太高了点,通过PIX分析之后,发现Wave占用率始终只能保持在97%左右,算下来刚好是实测值,观察反汇编代码之后发现编译器似乎在寄存器分配上有一点点过量,之后会试试直接用汇编来写看看能否跑满。
纹理与ROP吞吐率测试
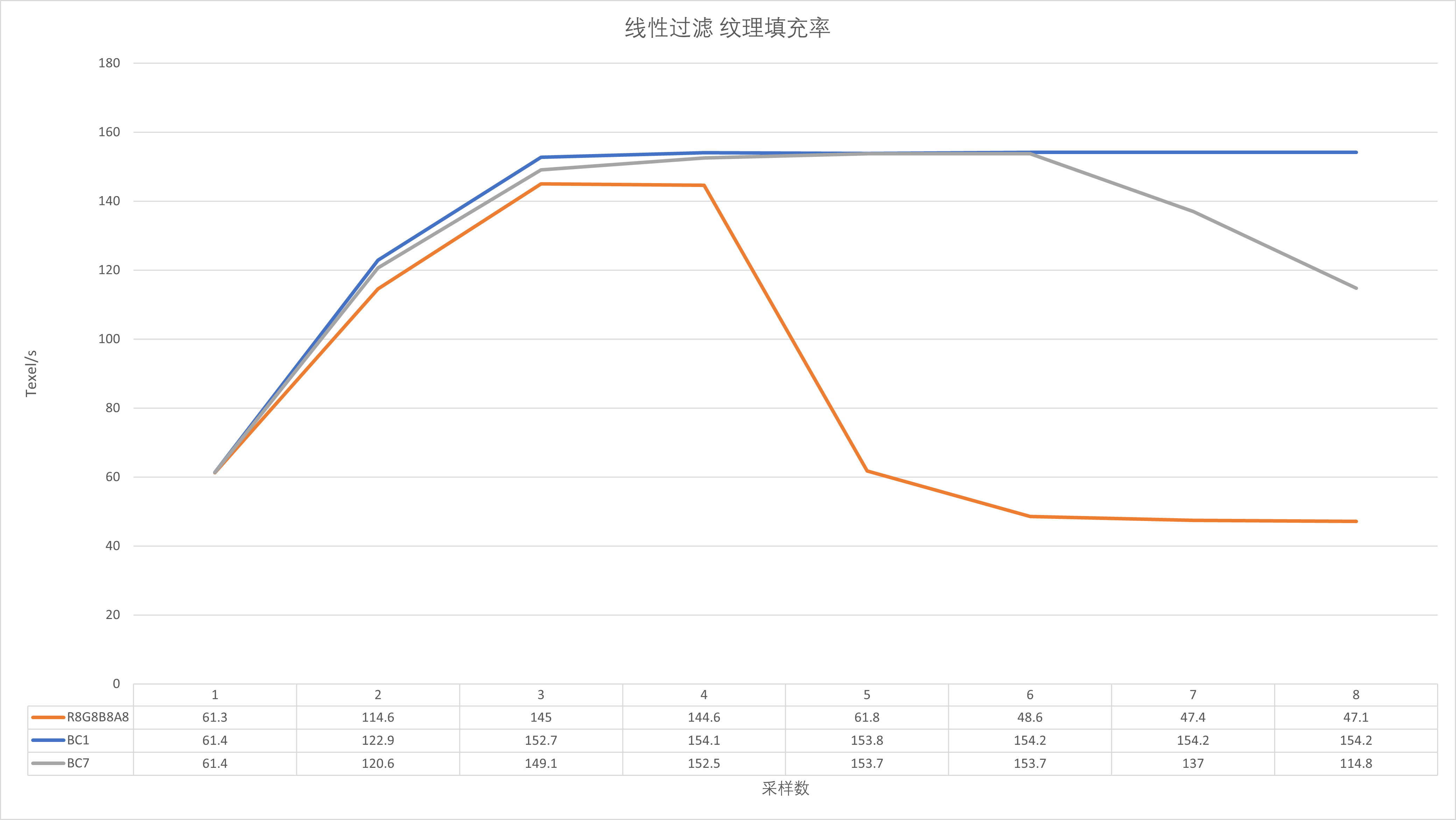
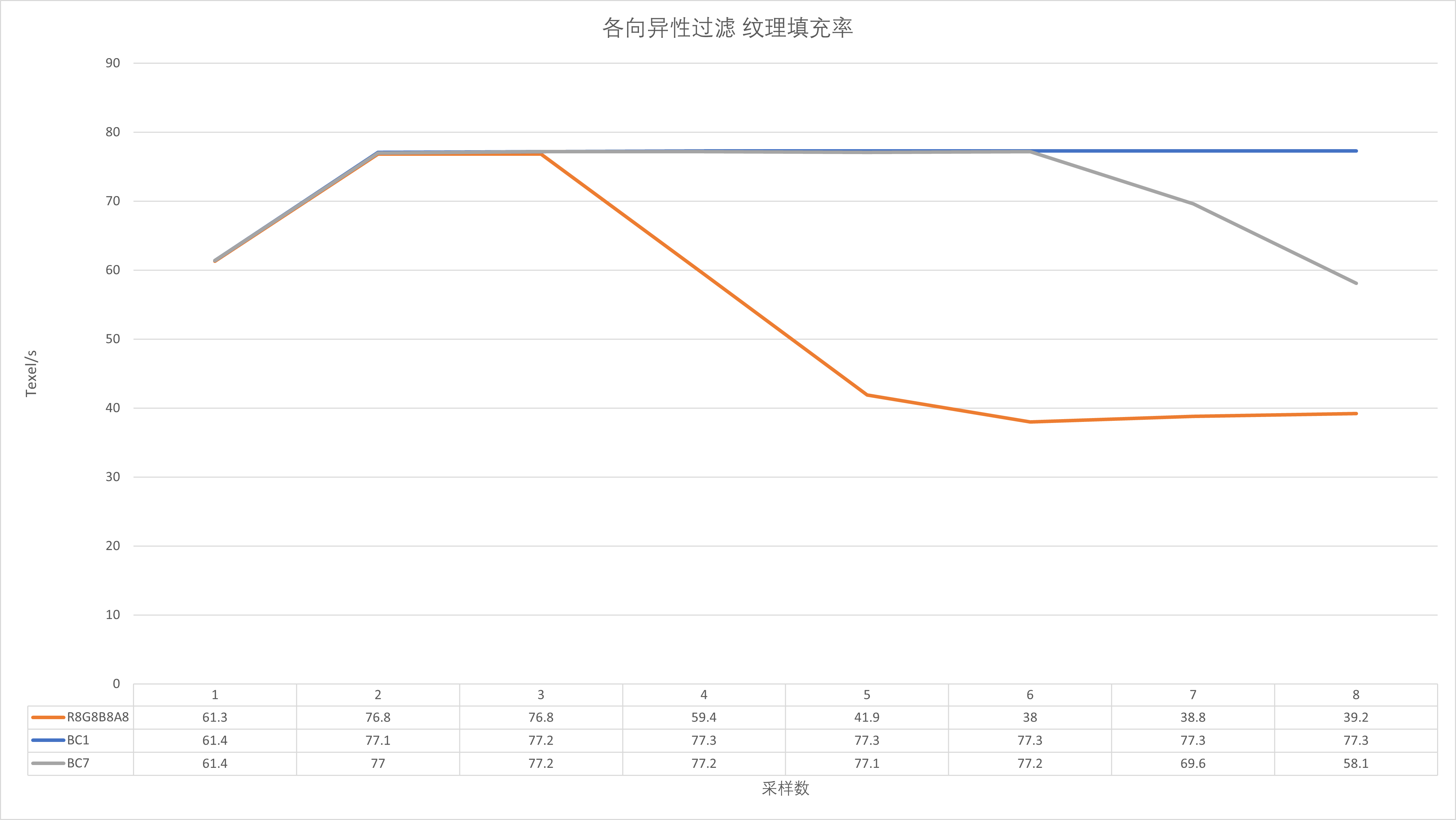
纹理测试峰值非常接近于理论值,测试纹理分辨率为800*800。观察一下的话可以发现,线性过滤在BC7格式下,Shader的纹理采样数大于6就开始下滑,稍微算一下的话,采样数为6的时候,纹理总容量为6*800*800 = 3840000,接近4M的L2容量,调整纹理分辨率可以达到同样的效果,这里可以看出DG2的纹理性能还是比较依赖于L2,这在A卡和N卡身上是基本见不到的。在各向异性过滤测试中,峰值性能基本直接砍半,这同样在A卡和N卡上见不到,各向异性过滤几乎都是免费的(但受制于显存带宽),这也可能是DG2在某些游戏中表现很差的直接原因之一。
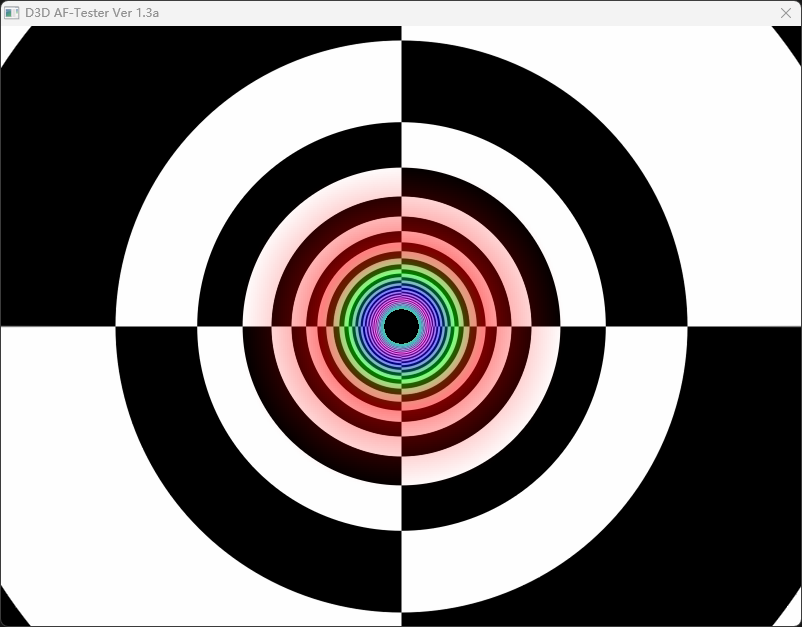
当然AF的效果还是很棒的,非常圆滑。
| 色彩填充率 | 62 GPixel/s |
| 深度填充率 | 153 GPixel/s |
色彩填充率离理论值78GPixel/s相差非常远,但是在用PIX或者GPA分析之后可以发现ROP其实都满载了,不知道是什么造成的这种现象,测试96EU的Iris Xe的时候也有同样的现象出现,1.1GHz的频率无论如何都只能达到21 GPixel/s。另外当渲染目标为屏幕的时候,DG2也启用了差分色彩压缩,避免了显存带宽成为瓶颈,在这之前,只有AMD的显卡可以做到这一点。
深度填充率,最传统的应用是改善高倍MSAA下的性能,从G80/RV770开始,深度填充率都是像素填充率的4倍,但是最近几年随着forward渲染的逐渐消失,硬件MSAA已经是个罕见的技术了,反而VRS这种“逆向”MSAA逐渐兴起,所以现在的显卡架构又改回了1:2的配置。Intel也不例外,深度填充率峰值达到了色彩的两倍多,但仅能在D16格式下实现,而D24S8或者任意32位格式下即便不启用模板,也仅仅能达一半不到的吞吐,大约72G Pixel/s,比较怪异。之后有时间我会慢慢研究。
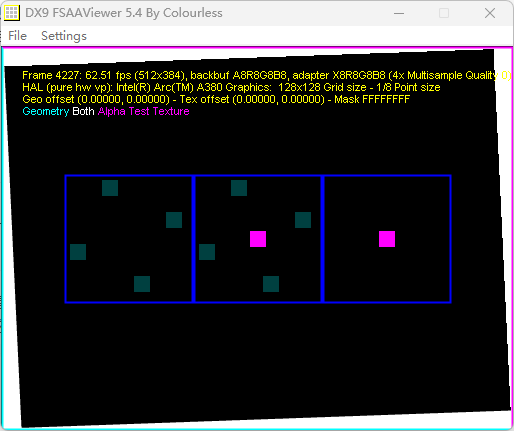
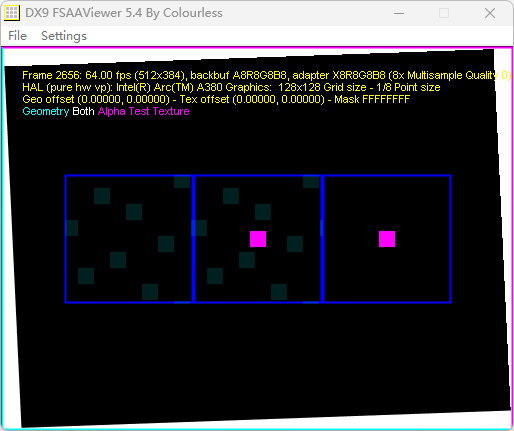
不同倍率下的MSAA的采样点。基本都是这样的了,没啥意思。另外不支持EQAA,当然这也是理所当然了。
多边形吞吐率
| 三角形吞吐率 | 4.38G Triangles/s |
多边形吞吐率比较接近理论值,算是不错的发挥,目前除了AMD在NGG Culling下可以完美达到双倍理论值的吞吐率外,别的情况下没有任何卡可以完美达到峰值,特别是Nvidia的显卡,比如GA104,理论值6每周期,实际最多做到4.69。
光栅化
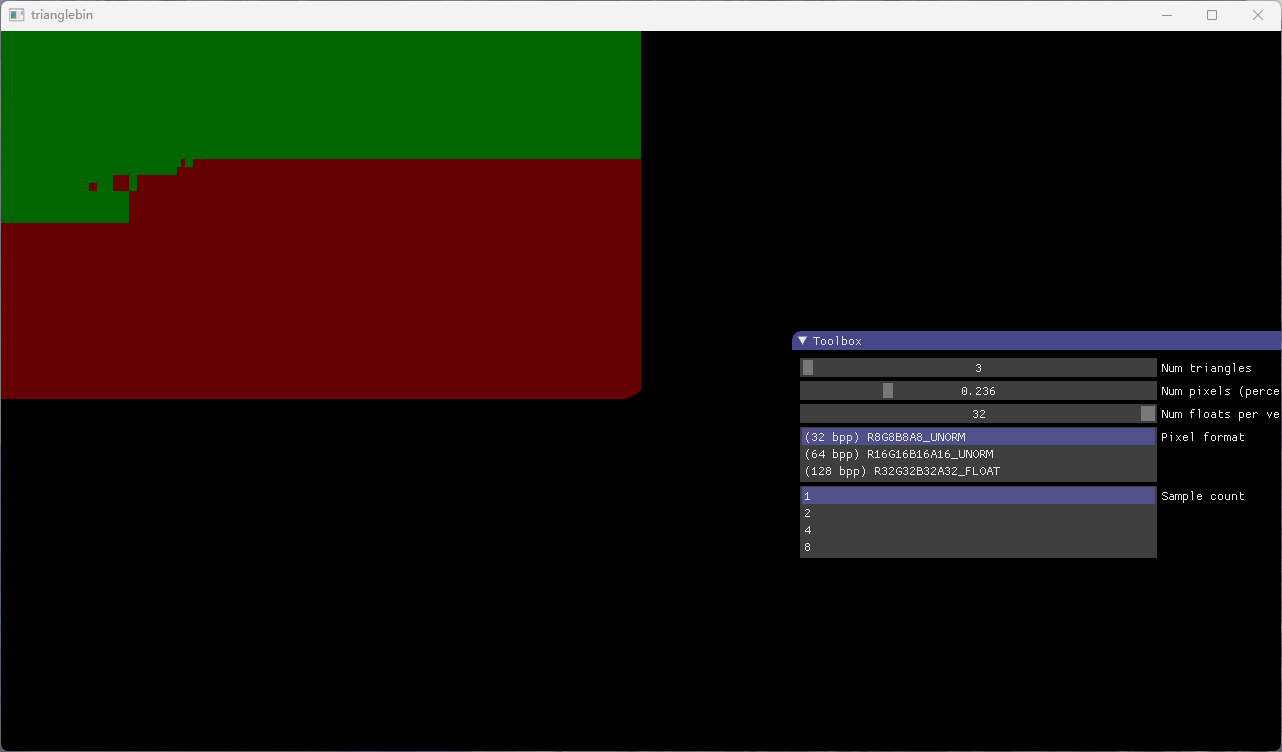
Nvidia在Maxwell 2上引入了Tile Based光栅化,实现了Tile Based Immediate Mode Render,随后AMD也用自己的方法实现了,AMD称之为Draw Stream Binning Rasterizer,和一般的Tile Based Render不同,这种实现并未将流水线分为两个阶段,而是将图元打包好一个块之后直接送给光栅器,然后前端Shader的输出则通过Parameter Cache送给后面的Pixel Shader,而不用全部生成好写回显存,比TBR进一步节约了显存带宽。当然,一些TBR有的缺点,这种模式也有,所以AMD只在了APU上启用了DSBR。
Intel在Gen11上引入了Position Only Shading Pipeline(POSh),这是一个简化版的前端Shader流水线,它由驱动生成,Shader方面只包含Vertex Shader,然后分块输出可见性信息到显存,然后正常的渲染流水线使用可见性信息先进行剔除,再完成整个渲染。可以算是一个非常特别的TBR与IMR的结合。这个流水线一直使用到了DG1。
POSh的劣势显而易见,虽然可以从开始就剔除一些图元,但毕竟多一个Render Pass,到底能不能节约资源还很不好说,同时正常的渲染流水线没有Tile Based,POSh还要浪费带宽,带宽节约无从谈起,所以DG2上POSh流水线被移除了。取而代之的是类似Nvidia和AMD的一样的TBIMR,如上图所示。Tile只有一级,它大小会根据Render Target的格式以及采样点数不同而调整,以确保可以放入L2缓存中。
目前的理论测试就到此为止,离我拿到卡已经快过去了一个月,大部分时间都花在了编程上面,后面等我有富余的时间,会再写一些测试程序,架构方面也会慢慢补充一些。顺便表扬Intel一点,就是他的软件非常给力,PIX支持很完美,不仅仅暴露了巨量的性能计数器给开发者,而且反汇编也提供,Nvidia虽然性能计数器也多,但是反汇编不开放给一般群众,AMD倒是开放反汇编,但是计数器也太敷衍了。Intel的GPA更是可以实时显示性能计数器的值并生成曲线,非常的爽。