Zen3架构介绍:
在AMD真正的翻身之作Zen2出来之后的第二年AMD又推出了它的改进版Zen3。这次的架构不再是一个单纯的改进版,而是一个融合了AMD各代处理器之长的全新架构,改进幅度相当的大,前所未有。下面我就简单的来介绍一下这次的具体改进。

- 取指部分

取指部分由分支预测器(橙色部分),控制给出预测的下一个指令地址,然后指令拾取(Fetch)拾取指令进入L1指令缓存。
L1指令缓存和之前一致依然是32KiB,8路组相连,32Byte每周期的带宽。但是改善了利用率和预取。和Intel明年将要发布的RKL相比,带宽上有翻倍的优势。
之后有一个指令字节缓冲,L1指令缓存以32Byte每周期的速度填满这个缓冲,这次AMD没有给出这个缓冲的大小,估计保持在Zen2水平,也就是16Byte*20,15Byte是X86指令的最大长度,所以这个缓冲其实是作为之后解码部分的取指窗口而存在的,能够保证装下至少一条X86指令。指令到达前面的指令字节缓冲之后,Pick部分则检查指令字节缓冲的前两个窗口,确定出其中x86指令,送给后方的解码器。
分支预测方面各个规格上的提升中规中矩,预测器类型依然是TAGE,L1 分支目标缓冲(BTB)从512槽位提高到1024槽位,而L2 BTB则从7K降到了6.5K,整体BTB的规模不变,但是因为第一级的容量增加,实际上降低了分支预测的延迟。间接目标阵列(ITA)从1K提高到1.5K。除开规格上的提升,分支预测部分最大的改进在于,消除了绝大多数的分支预测气泡,分支预测气泡会影响乱序核心的工作,导致分支前后指令无法完美乱序执行,这对于很短的分支来说(比如很短的循环)有很大的改进。
- 解码部分
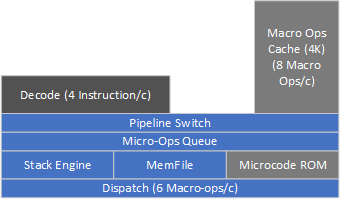
解码部分从传统解码器开始,每周期解码最多四条X86指令,每条X86指令解码出一条或多条Macro-op宏操作,送进Micro-ops queue。(感觉叫Macro-ops queue是不是比较好?)
Macro op:K5开始AMD为了性能引入更先进的精简指令集(RISC)内核(其实就是自家的RISC处理器Am29000)。这个精简指令集的内核有一套自己的指令集,在X86处理器中,AMD将他称为RISC86,RISC86指令也就是我们所说的Macro op。X86指令进入解码器之后,解码器就会将他翻译为一个或者多个Macro op。
Micro op:Macro ops依然不是直接可以直接给硬件执行单元执行的指令,硬件执行单元需要更细的指令,比如需要访问内存中数据来作为操作数的加法Macro op,那么我们需要让这个Macro op生成一条控制加法器的指令,一条控制访存单元(LSU)的指令,生成的这些指令就是Micro op。一条Macro op可以翻译为一到多条Micro ops。
μop :Intel同样为了高性能引入了RISC内核,但Intel直接将X86指令解释为类似AMD的Micro op的东西,Intel将他称为μop。
传统上AMD把X86指令分为三类,fast path single,fast path double,microcode。fast path single解码出来一条Macro op,fast path double两条,这两种都可以由任意一个解码器在一周期内解码完成,但不能超过6 Macro op的总带宽。microcode则需要由micro code rom来生成两条以上的macro op。从Zen2开始因为SIMD扩宽为256bit,不再需要拆分执行,所以fast path double的指令已经极难看到了。
Intel的RKL的解码器由一个复杂解码器和四个简单解码器组成,生成μop数量大于1小于4的指令由复杂解码器解码,等于1的可以由任意解码器解码,总计5 μop的解码器总带宽。大于4的则由MSROM解码。
解码出来的这些宏操作在被送往执行单元之前,会先被堆栈引擎stack engine和memfile处理,stack engine主要处理push、pop、call、ret之类的堆栈相关的指令,memfile则通过寄存器重命名特性来处理寄存器移动mov reg,reg之类的指令,实现Register move eliminate 寄存器移动消除的效果,节约了之后Dispath的带宽、执行单元占用以及功耗。而需要送往执行单元的宏操作,则由分配器Dispatch送往整数或者浮点执行单元,最高六个宏操作每周期。
与此同时,Macro-ops cache宏操作缓存,会把解码器出来的Macro-op缓存起来,最多可以提供4K个位置给Macro-op。一旦遇到合适的情况,便会停止传统解码器,交由Macro-ops cache来为之后的流水线提供Macro-op,带宽峰值可以达到传统解码器的两倍,而且还能节约电力。Macro-ops cache容量和速度都没有变化,但提高了拾取操作排队的速度。相对于Intel下代RKL,容量上有近两倍的优势,带宽上也有33%的优势。
同时Macro-ops cache和传统解码器之间的切换也变得更快,因为切换速度快了,Zen3的切换条件也给的更加细致宽松以便让切换更加频繁,提高Macro-ops cache的利用率。
CLASP:https://pdf.bban.top/downloads/2021-05-16/16/kotra2020.pdf?rand=613aeaf1c2d02?download=true
- 乱序引擎

从前一阶段的分配器出来的宏操作,会根据类型被分别送到整数和浮点引擎,他们都被一个统一的Reorder buffer重排序缓冲区跟踪记录,重排序缓冲区会记录指令和它需要的寄存器、目标操作数、结果、执行状态,并且保证指令按顺序被retire回退。Zen3将ROB的大小从Zen2的224提高到了256,但距离RKL 352还有相当的差距。ROB的retire带宽则是AMD的传统强项,Zen2是8,Zen3没有透露,但肯定也大于8,RKL只有5。
Rename重命名将Physic Register File物理寄存器堆中的寄存器重命名为指令所需的X86架构寄存器。Rename带宽Zen2的整数和浮点分别是6和4,而Zen3实测提高到了6和6,Intel没有分成整数和浮点两块,RKL上带宽是5。
Reservation station/Scheduler保留站或者说调度器,检查源操作数就绪状态,如果就绪,则被送往执行单元执行。执行完毕的指令由重排序缓冲区顺序完成。整数方面的保留站使用了全新的设计,这个设计类似早年间AMD自家的K7-K10这一系列的架构,每个ALU搭配一个AGU或者BR分支指令单元共用一个保留站,每个整数保留站的大小都为24槽位,总计96槽位,这样做使调度器的利用更加的均衡。在Zen2中4个ALU都有自己独立的保留站,每个16槽位,三个AGU则共用一个保留站,28槽位,RKL的不详。浮点这边的保留站大小没有公开,但数量从之前的1个变为2个,考虑到浮点发射数量从4变为6,这个改变非常的有必要。
整数寄存器堆的大小从180槽位变为192槽位,浮点不变。
最后AMD提到了使用了一个新的Picker(不太懂这是什么)提高了整数Pick带宽?
这里和去年一样,我们来实测一个ROB的大小,不过今年不再使用aida64的工具:
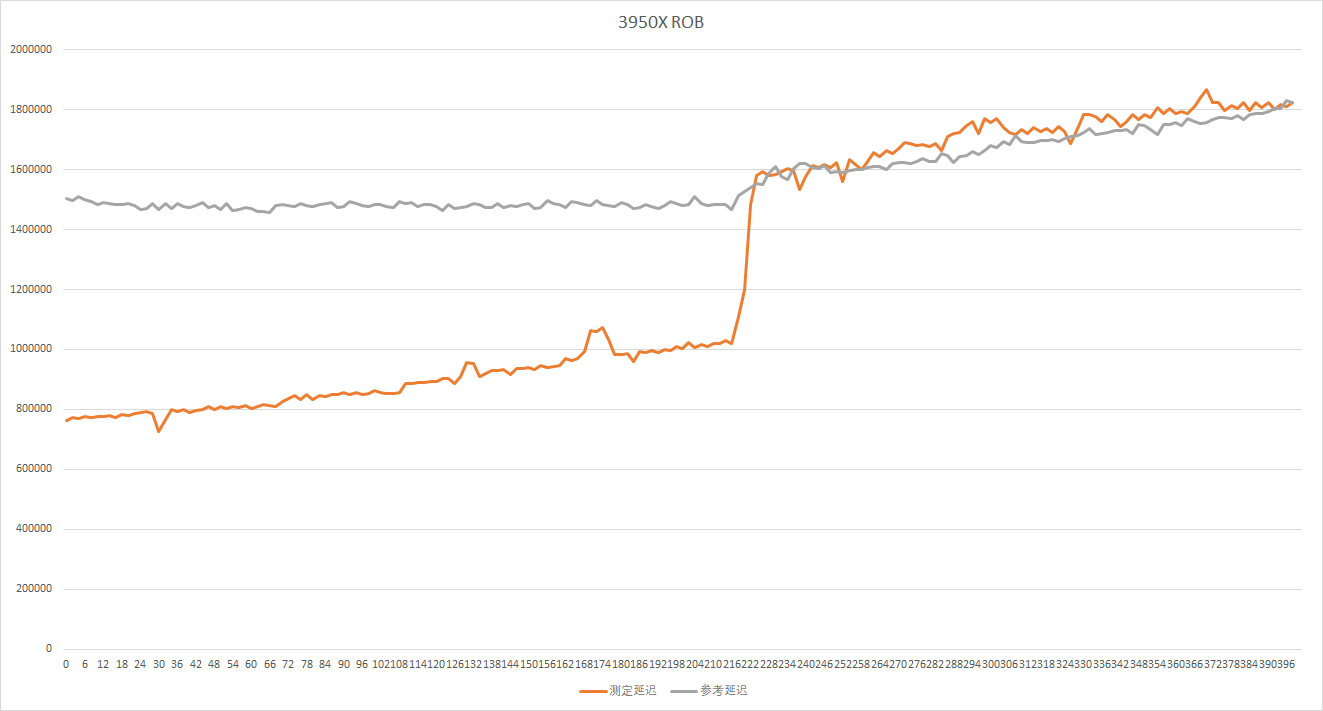
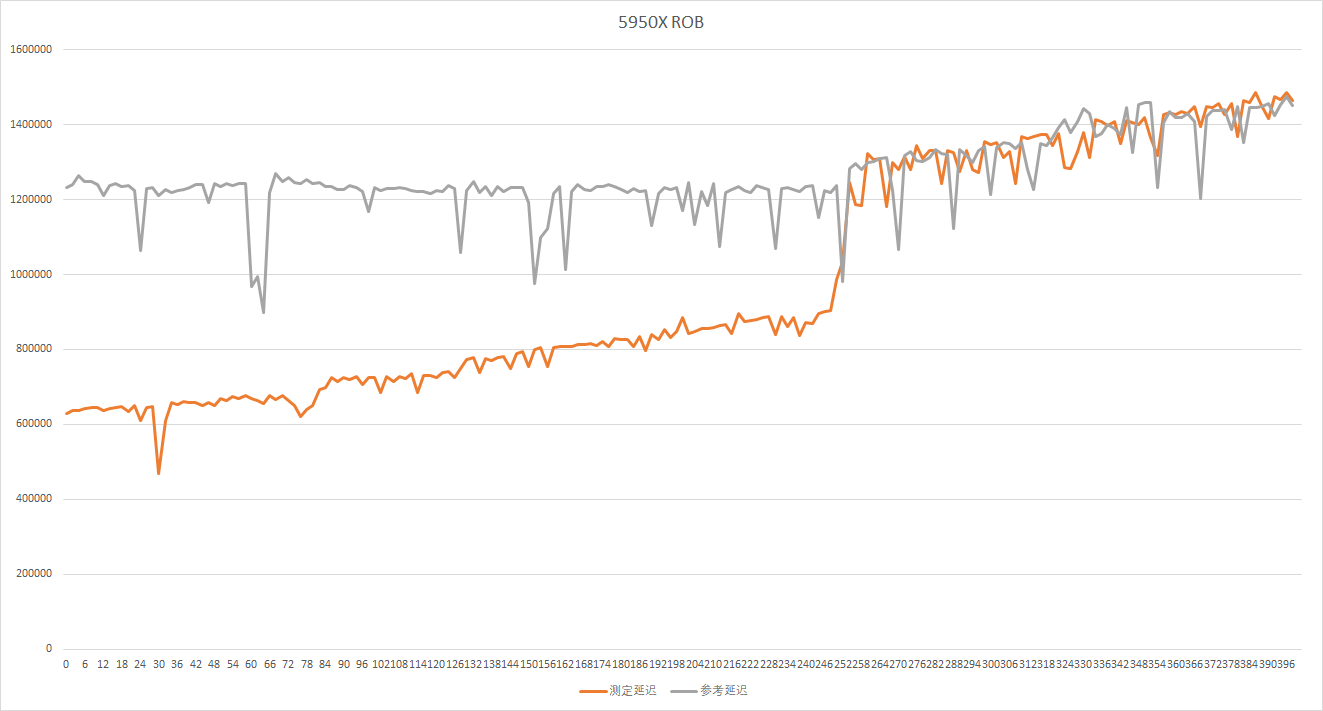
可以看到都在各自官方数据的点上出现了延迟抬升,符合预期。
接着我们再测一下峰值IPC:
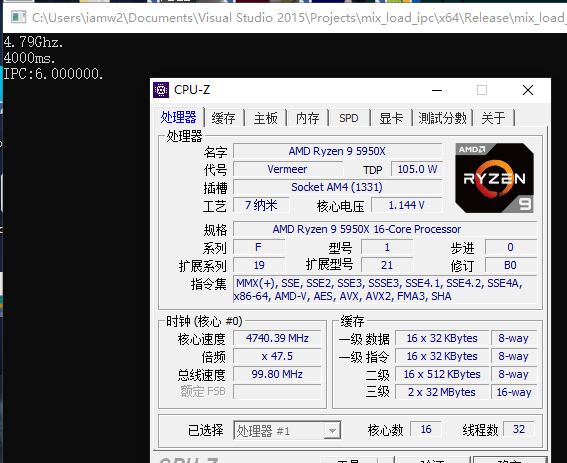
自从Zen1第一次实现X86 5发射的纪录之后,Intel的桌面端终于将在明年出世的RKL上追上AMD,但现在Zen3出世又打破了这个纪录,成为第一个实现不依赖宏融合真实达到6发射的X86处理器。
这里Zen2我借用了去年3900X的图,因为Zen2上要调整指令组合到跑满他的IPC太过于困难了,需要浮点整数混合仔细调整。Zen3因为分支部分消除了大部分的气泡,而且单单使用整数就能轻松跑到峰值,所以指令啥的随便凑凑就能跑到6的峰值。
- 整数执行单元

整数执行单元,接收从RS过来的micro op并执行。这部分的改进一眼就能看出来:
执行单元又变多了。在Zen2中,有4个ALU和3个AGU。而Zen3中增加了一个发射端,给一个独立的分支指令单元,BRU1。但这也不是改进的终点,AMD在AGU2和ALU1上增加了两个Store存储单元。Store不占用该发射端,可以与AGU2和ALU1并行。所以实际上整数部分可以达到10个微操作发射数每周期。考虑到没有和浮点争用端口的情况,这大概是X86史上最屌整数执行单元部分了。除开宽度,某些指令的延迟和吞吐也得到了优化,见下表:
| 5950X | 3950X | RKL | ||||
| 延迟 | 吞吐率倒数 | 延迟 | 吞吐率倒数 | 延迟 | 吞吐率倒数 | |
| ADD reg,reg | 1 | 0.25 | 1 | 0.25 | 1 | 0.25 |
| MOV m,r | 4 | 0.5 | 4 | 1 | 5 | 0.5 |
| MOV r,m | 4 | 0.33 | 4 | 0.5 | 5 | 0.5 |
| XCHG r,m | 7.5 | 7.5 | 18 | 18 | 20 | 18 |
| LOCK ADD m,r | 6.5 | 7.5 | 18 | 18 | 20 | 18 |
| IMUL | 3 | 1 | 3 | 1 | 3 | 1 |
| IDIV | 7-19 | 7-19 | 14-45 | 14-45 | 6-18 | 6-18 |
| AND | 1 | 0.5 | 1 | 0.5 | 1 | 0.33 |
| LEA | 1-2 | 0.25-0.5 | 1-2 | 0.25-0.5 | 1 | 0.25-0.5 |
| PUSH | 0.5 | 1 | 0.5 | |||
| POP | 0.33 | 0.5 | 0.5 |
从这张表可以看到除开上面提到的改进,另有一个非常瞩目的点,所有的原子指令,比如LOCK ADD,XCHG之类的,延迟和吞吐都从18周期降低到了7.5周期,是个非常大的改进,对于多线程程序的线程同步会有很大帮助。
- 浮点执行单元

与整数部分类似,浮点部分也扩宽了执行单元。将浮点整数转换指令的执行单独提出来,做了两个F2I执行单元,并且加上了一个独立的存储单元,但这个存储单元并不能并行,所以浮点部分总宽度是6。相对于上代来说提高了50%之多。除此之外,继Zen2改进FMUL指令延迟之后,这次FMA指令的延迟也得到改善,从5周期优化到了4周期。当然也同整数一样,加了发射端自然要优化各个发射端中的指令配置。实际测试见下表:
| 5950X | 3950X | RKL | ||||
| 延迟 | 吞吐率倒数 | 延迟 | 吞吐率倒数 | 延迟 | 吞吐率倒数 | |
| VADDPD | 3 | 0.5 | 3 | 0.5 | 4 | 0.5 |
| VMULPD | 3 | 0.5 | 3 | 0.5 | 4 | 0.5 |
| VDIVPD | 13.5 | 4.25 | 13 | 5 | 14 | 8 |
| VFMA | 4 | 0.5 | 5 | 0.5 | 4 | 0.5 |
| VCVTDQ2PD | 4 | 0.5 | 4 | 1 | 7 | 1 |
| VCVTPD2DQ | 6 | 0.5 | 6 | 1 | 7 | 1 |
| VMOVAPD m,r | 1 | 1 | 1 | |||
| VMOVAPD r,m | 0.5 | 0.5 | 0.5 | |||
| PDEP | 3 | 1 | 19 | 19 | 3 | 1 |
| PEXT | 3 | 1 | 19 | 19 | 3 | 1 |
| VPAND | 1 | 0.25 | 1 | 0.25 | 1 | 0.33 |
| VPADDUSB | 1 | 0.5 | 1 | 0.5 | 1 | 0.5 |
| VPCMPEQB | 1 | 0.25 | 1 | 0.33 | 1 | 0.5 |
- 存取单元

存取单元主要是接收来自执行单元的访存请求,将请求的地址使用TLB加速求出真实地址之后进行数据存取。
L1D保持规格不变,依然8路组相联,64Byte/c读带宽,32Byte/c写带宽,但Zen3带来了一个关键性改进,请求不超过64bit的情况下(AMD说的不是256bit的情况下,但实测只能64bit和以下),现在访存单元最多可以接收3读或2写(Zen2位2读+1写),访存指令可以执行的非常灵活,比如2+1,1+2,3+0啥的。Rocket Lake相比,RKL可以做到2读加2写,各有优势,但AMD的应该更加符合传统使用场景,因为一般来说很少有读写比例一致的情况,都是读取多于写入。
同时LSU增强了数据依赖性检测,增加了4个TLB walker来应对更多的访存操作。读队列Load queue保持不变,然后写队列Store queue从48提升到了64,想来是为了适应翻倍的写吞吐率。