- L2/L3缓存以及互联

Zen3的L2缓存与Zen2的保持一致依然是512KiB 8路组相连,读写吞吐率也保持在32Byte每周期,为包含式缓存。
Zen3的改动重点在于L3缓存。AMD想把Zen3的CCX扩大到8个核心,以便得到一个更大的共享缓存,但AMD以前CCX中所使用的Crossbar互联要扩大到8核心的话,复杂度和功耗都会极大的增加。所以AMD这次选择了另一条路,就是Ringbus。关于这部分AMD提的很少,基本信息只有读写带宽依然保持在32Byte每周期,延迟从以前的39周期提高到了46周期,L3依然作为L2的Victim。这里我们通过一些测试来研究一下L3缓存以及他们的互联。
首先是缓存延迟的曲线图
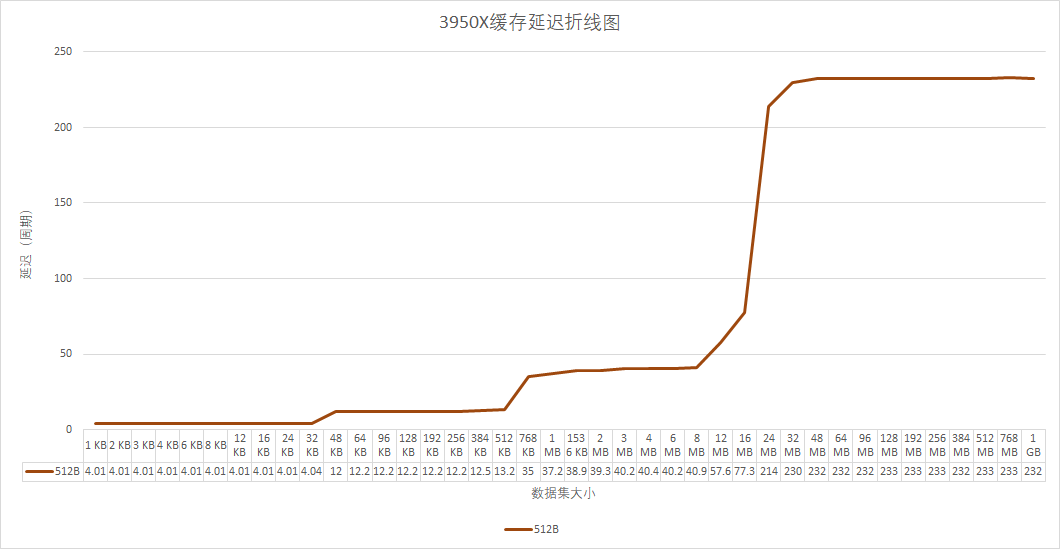
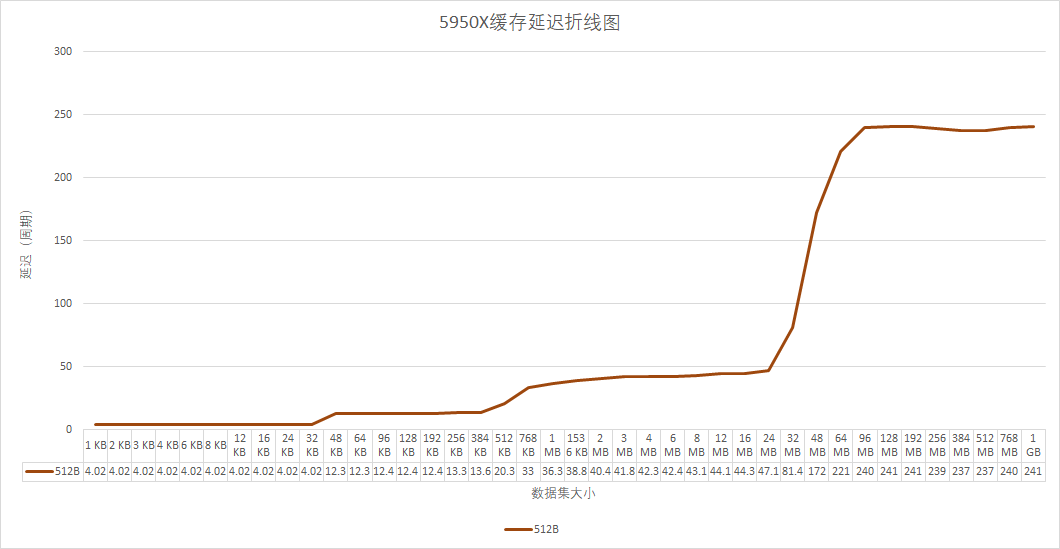
Zen3的延迟没有什么悬念,都符合AMD的描述,因为容量更大,所以最终进入内存延迟的时间也更晚32M才开始大幅攀升,这对于游戏等访存的foot print比较大,而对延迟又敏感的程序来说有非常打的帮助。有趣的是,我在使用不同的stride长度的时候,Zen3的L3缓存表现出了和Zen2截然不同的反应。
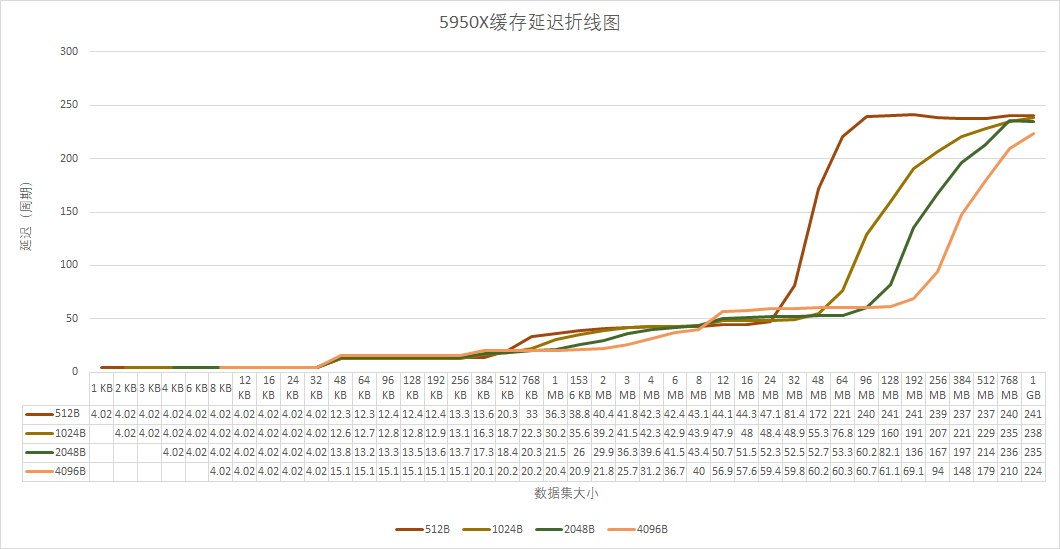
Zen2中无论stride长度如何,进入内存的点都在16M附近,变化很小,而Zen3中随着stride增大,进入的点也随之增大,4096Byte的stride甚至到了1G左右都还没有完全进入内存延迟范围。看来Zen3在缓存的预取策略和淘汰策略上都有不少的改动。更具体的,我会空闲下来之后细细研究。
接下来看看互联的情况,这次换用了Ringbus,所以我对互联的表现很感兴趣。Zen3的Ringbus和Intel的Ringbus有些不一样,Zen3的Ringbus不需要连接过多的设备,只有8个核心和一个GMI2接口,Intel的则需要连接多个核心、iGPU、内存控制器、PCIE控制器、和一堆外围设备。所以我对AMD的Ringbus延迟还是比较有信心的。PingPong测试具体结果如下:
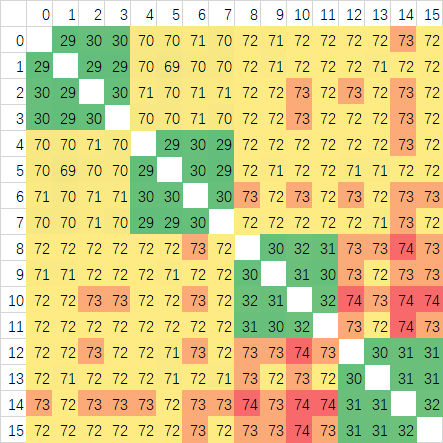
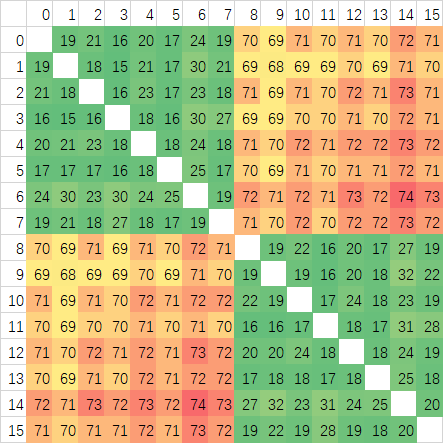
这里可以看到CCX内的延迟,Zen3的平均延迟比Zen2更低,因为8核心一个CCX,所以低延迟部分覆盖范围相比Zen2翻倍了。不过从图上可以看到波动非常大,感觉上是Ringbus的导致的。但有些不确信,所以又做了一个定频3Ghz的测试:
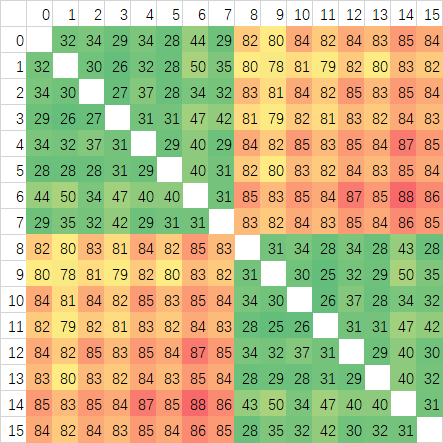
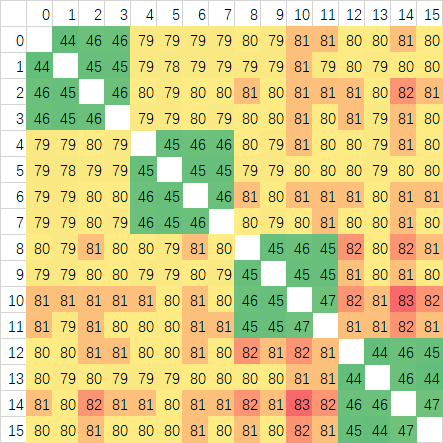
这样可以明显的看到确实是延迟波动非常大,Ringbus的特性无误了。CCX内的平均延迟5950X有明显的优势,仅为33ns左右,而3950X高达45ns,提升非常大。
Ringbus和Crossbar不同,按Intel的做法,Ringbus需要将数据打散放在各个L3 Slice中,发出访存请求之后由近到远的访问,这里我们来研究一下AMD的策略,我使用一个修改版的PingPong程序进行测试,结果如下图:
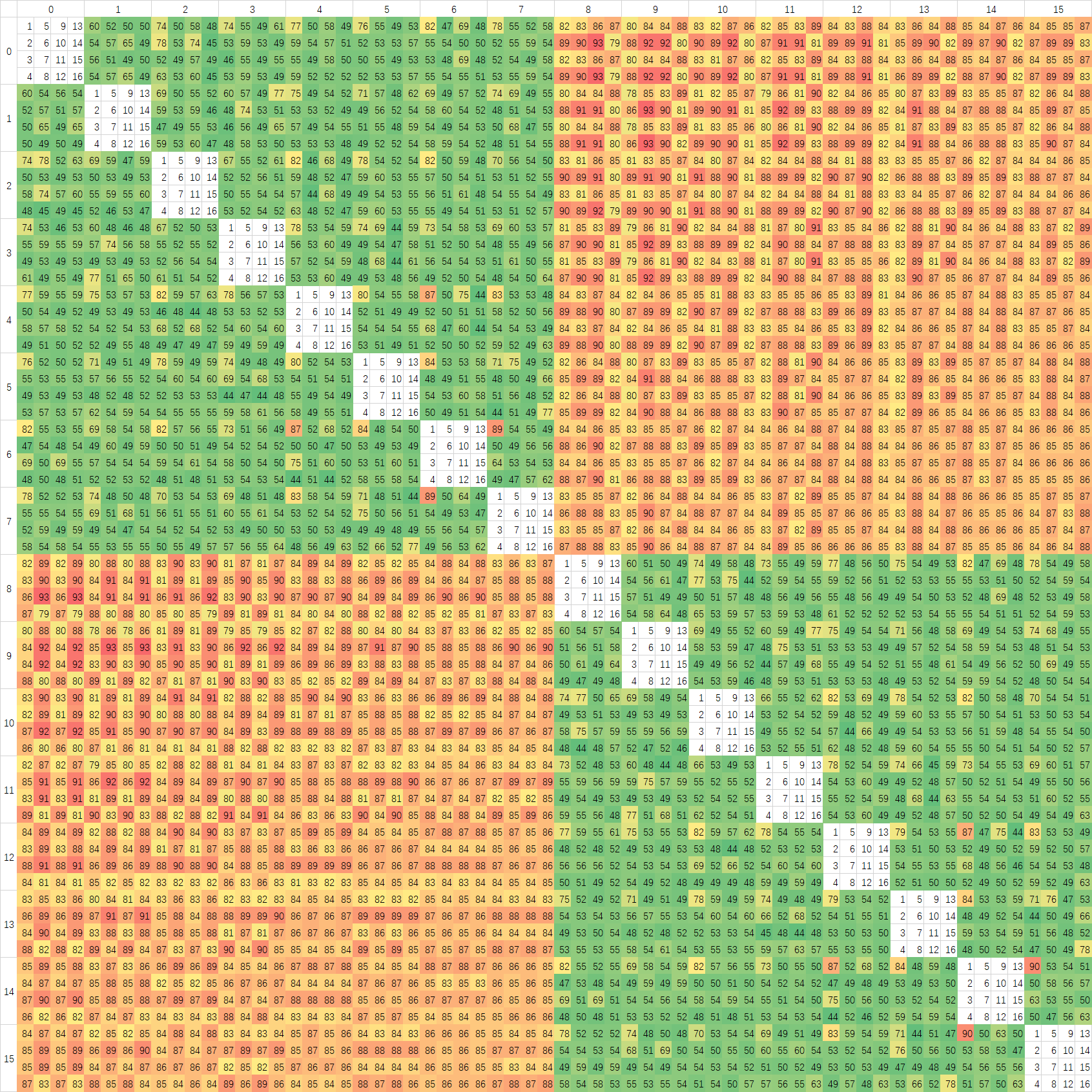
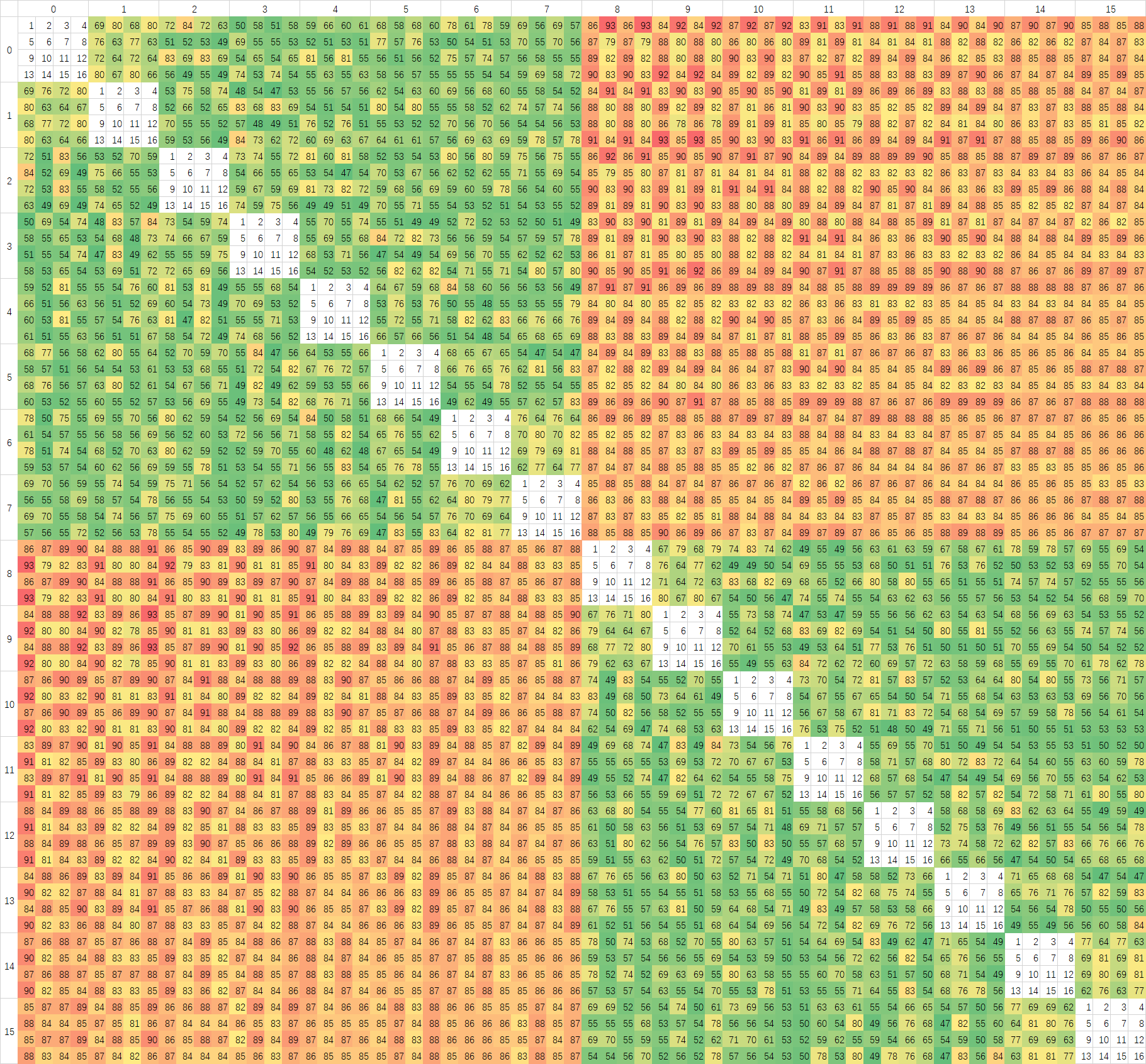
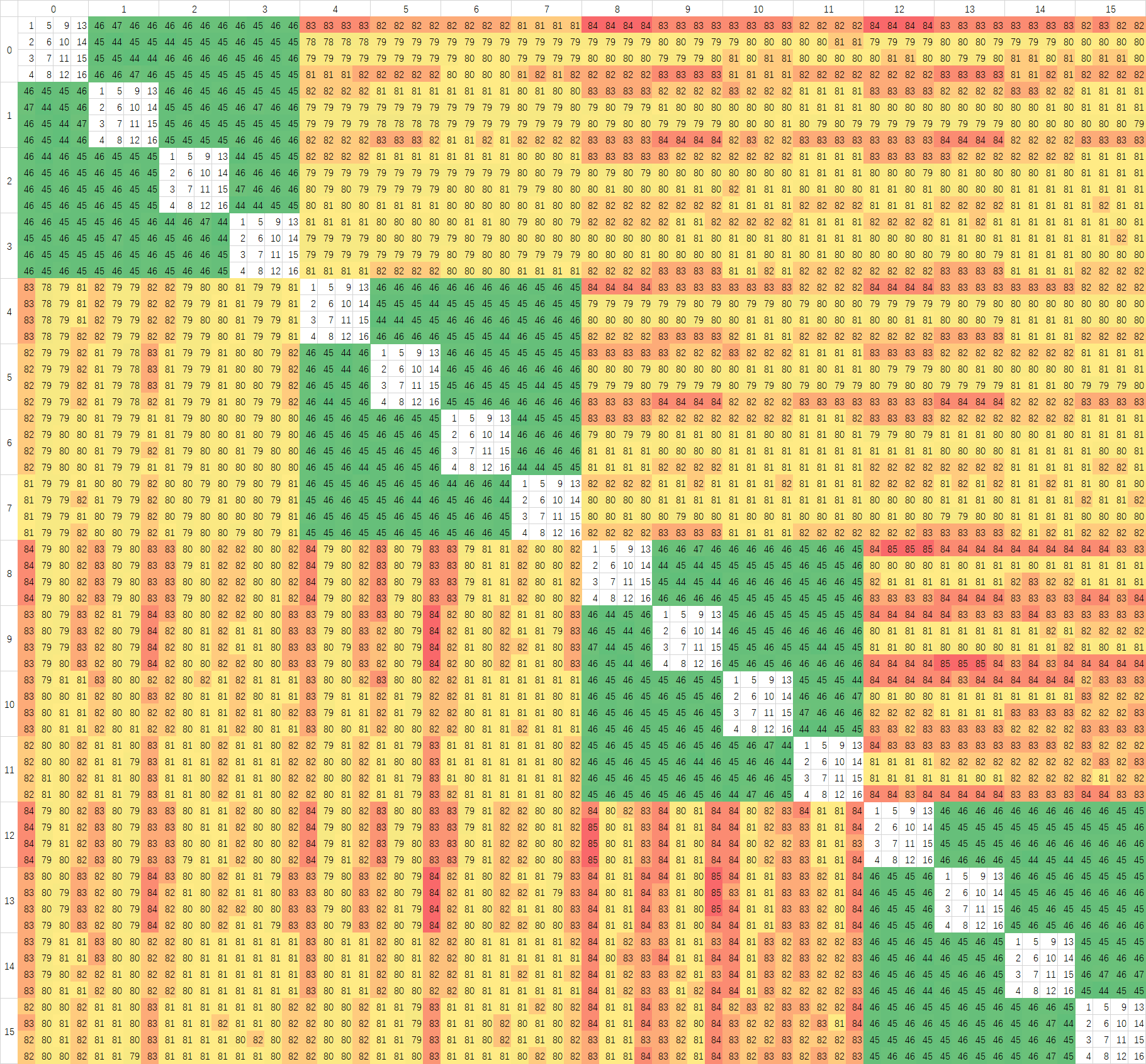
测试频率同样保持在3Ghz,但是测试方法有所不同,在预热好的Buffer中,我取前16个Cacheline进行PingPong测试,这样数据会从L3绕行一圈。图中我已经在空白部分用1-16的数字标出了16个Cache Line对应的位置。第一张有BUG的图中可以看到,每个核心对进行测试时,第一个Cache Line的延迟总是最高的,我一开始以为是预热不到位,但是测试发现跑两遍去第二遍也是一样的结果,检查代码之后发现给测试用的Buffer的对齐代码,写到别的变量身上去了,不过从这里也可以发现,Zen3似乎只会把访问地址开始后的第一个对齐地址之后的数据放在缓存上,Zen2上没有这个问题,说明替换策略有所变化。
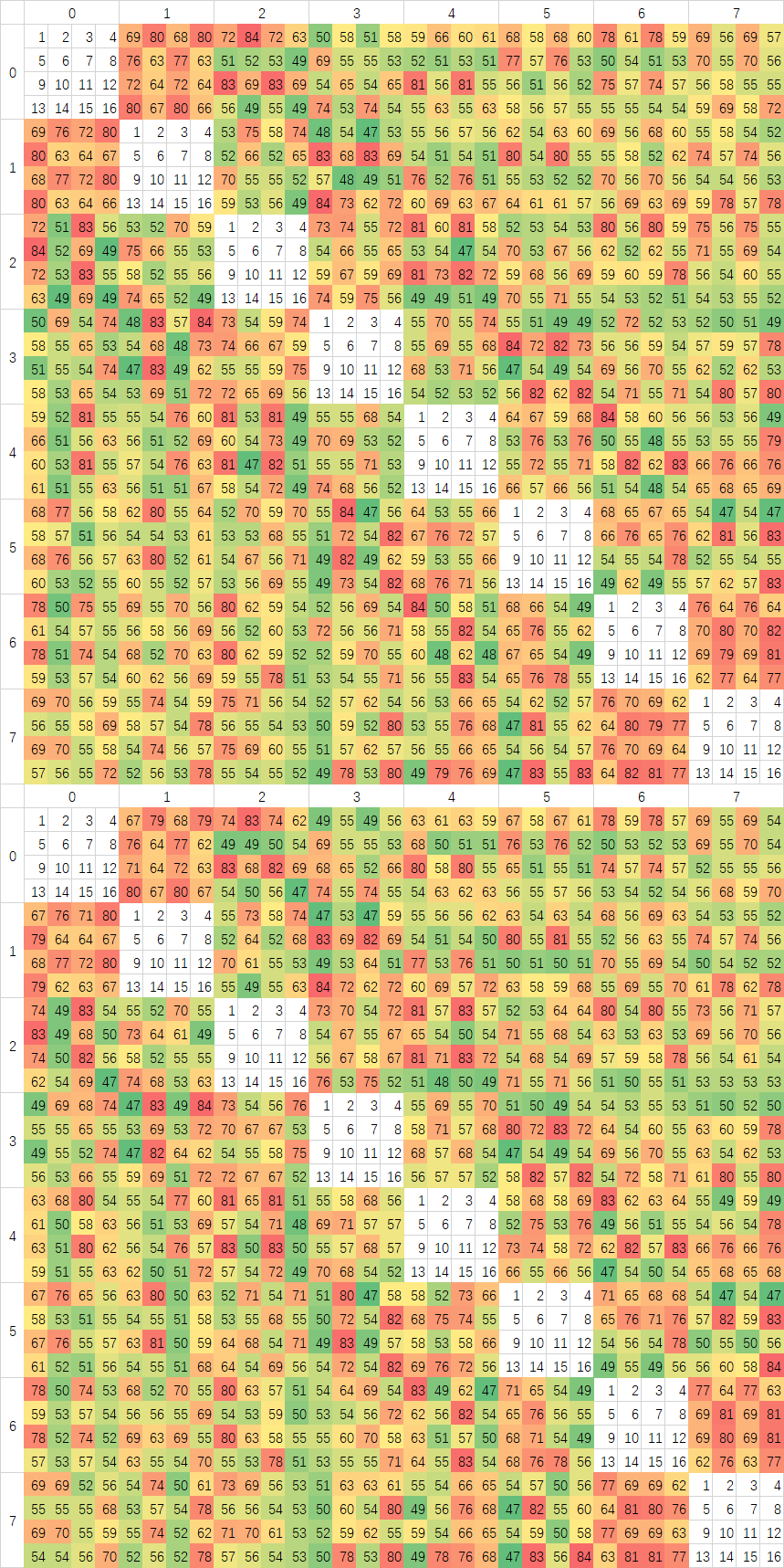
上面是修正后测试中CCX内部分。大部分核心对中,前八个与后八个Cache Line几乎可以重合,说明AMD是将地址以Cache Line为粒度分散在每个CCX中八个核心对应的的八个L3 Slice中的。CCX内的延迟,在Zen3上面波动很大,应该是L3的特性导致的。我同样在Intel的处理器上进行过测试,但没有这么大的延迟波动,很平均,说明Intel的L3 数据分布粒度比Cache Line要小,以Cache Line为粒度还不足以测试出,只能测试出一个平均值。
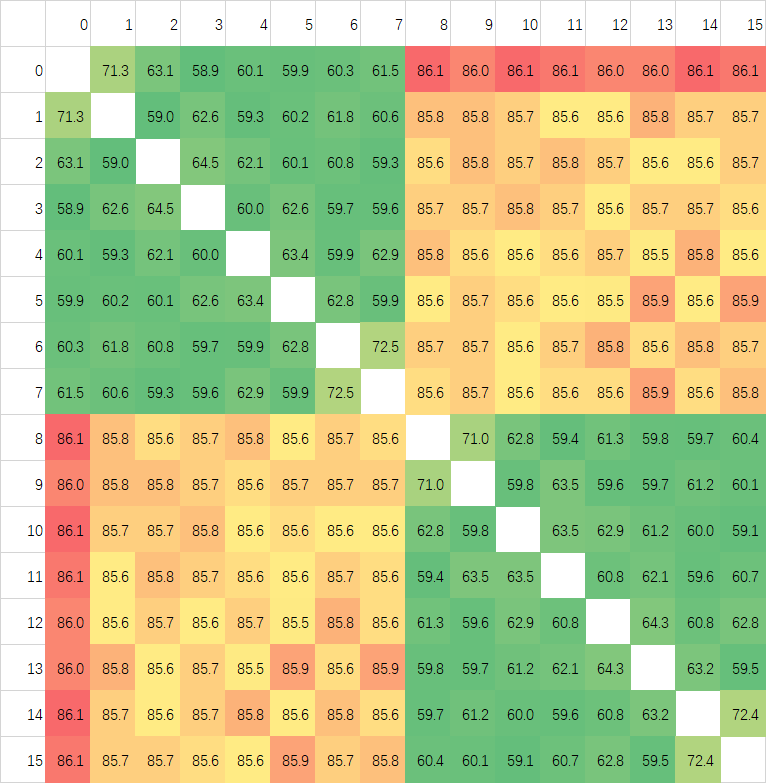
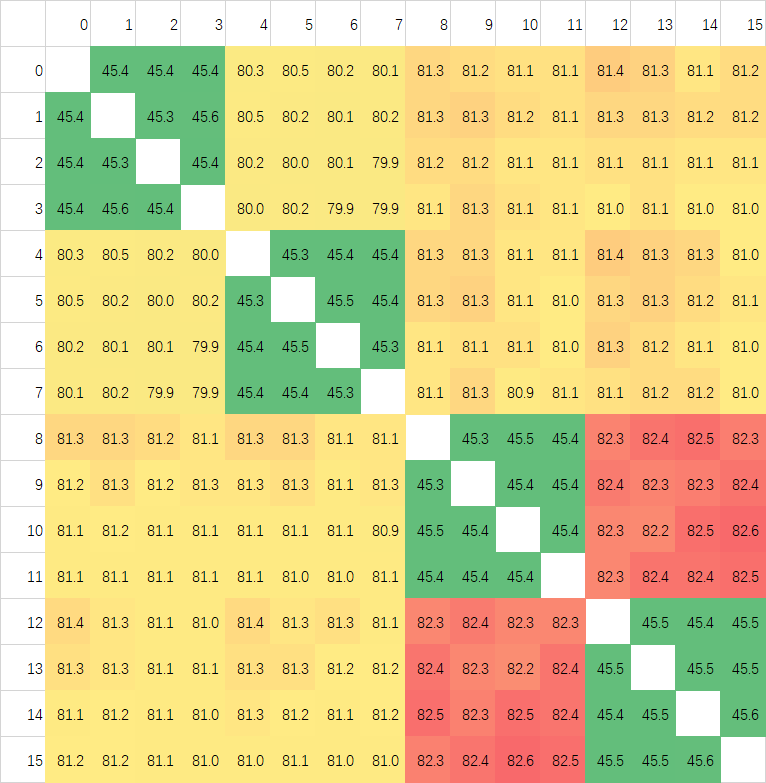
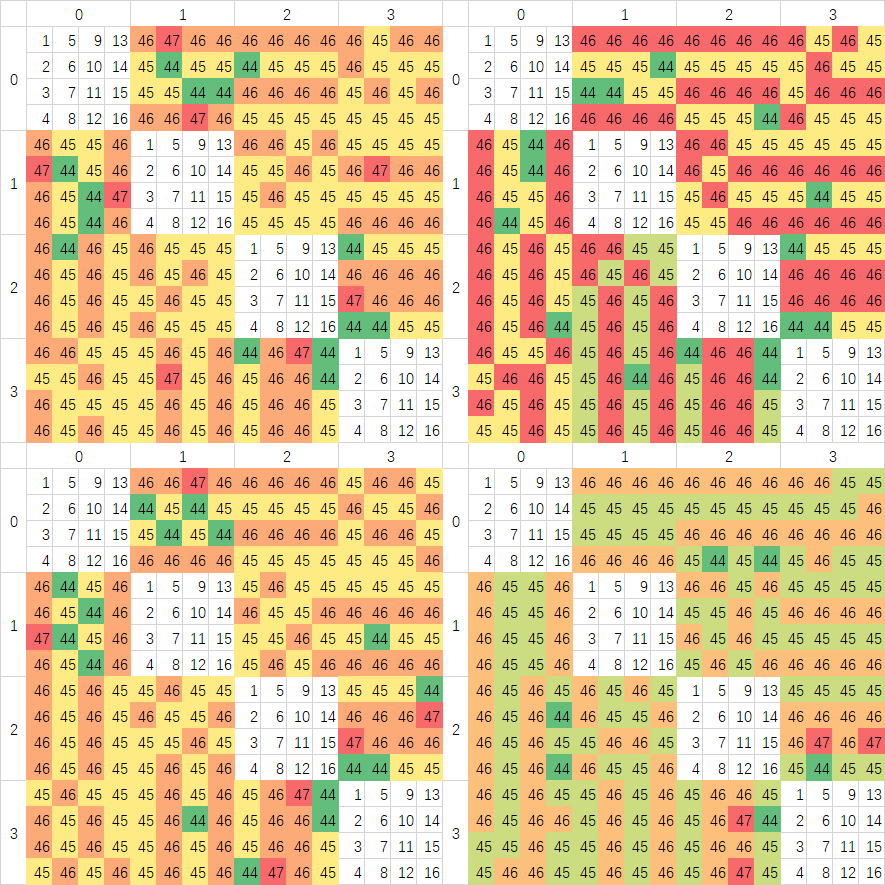
最后我取每个核心对之间的16次测试做了一个平均,生成了最后一张图,可以看到延迟波动就比较小了,说明对于较大粒度的数据进行核间传输的时候Ringbus也是可以保持稳定的。而Zen2,应该是以Cache Line为粒度地址分布在几个L3 Slice中,但因为使用Crossbar互联,延迟波动几乎没有,是最为稳定的架构,虽然整体的平均延迟比较高。

CCD互联方面,完全与Zen2保持一致,按AMD自己的说法,cIOD就是Ryzen 3000上面的那一颗。CCD通过上行32Byte/c 下行16Byte/c的GMI2总线与IOD互联。每颗CCD由IF总线的CCM和CS来维持缓存一致性和正确的访存。核心之间互联的时候,因为需要通过CS来维持一致性,所以互联延迟会比较高,差不多是内存延迟的样子。SDF和MC之间的链接速度为32Byte/c。IO方面则使用非一致性链接,速度为64Byte/c。我们用AIDA64实测一下来看看这部分的性能。
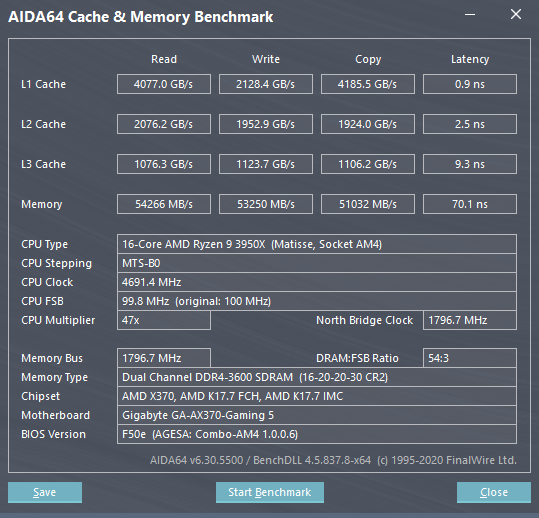
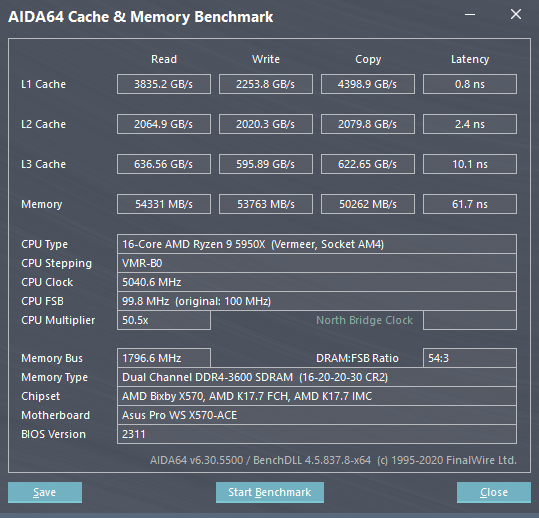
可以看到内存带宽上,两者表现几乎一致,但是在延迟上,5950X比3950X低了9ns,对于延迟敏感的的程序,比如游戏之类的,有很大的帮助。L3缓存方面,因为互联改为Ringbus,带宽上受到了不少的影响,几乎只有3950X的一半,对于数据集比较大的SIMD计算密集的程序可能会有一些影响。延迟上5950X也稍高一点点,但是考虑到等效翻倍的容量,这应该是个不错的Trade off。
架构部分就到此为止。因为AMD的Profile工具还没有更新,等更新之后,我也会附上一些理论性能的测试给大家。