- 访存单元(LSU)和缓存结构
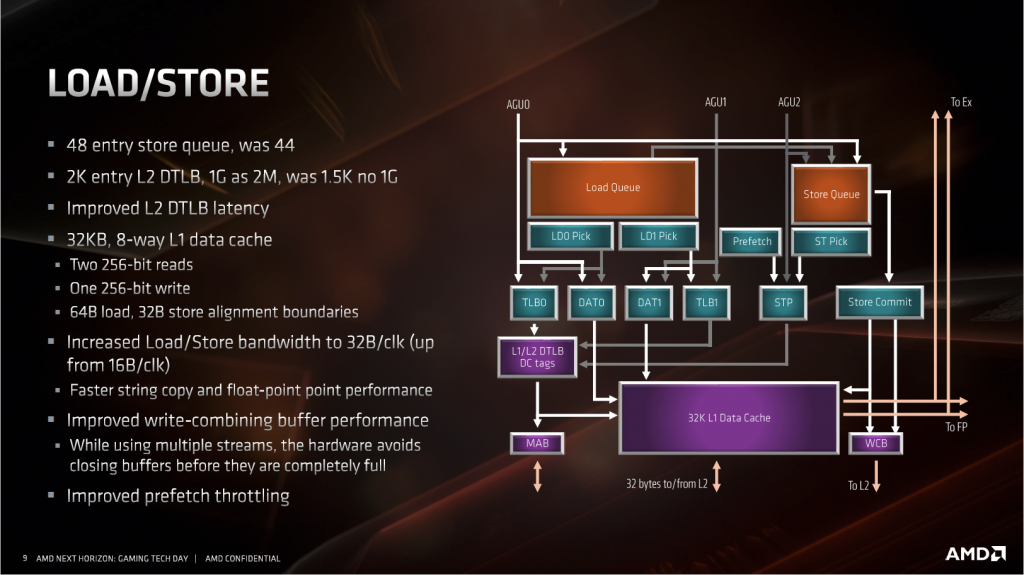
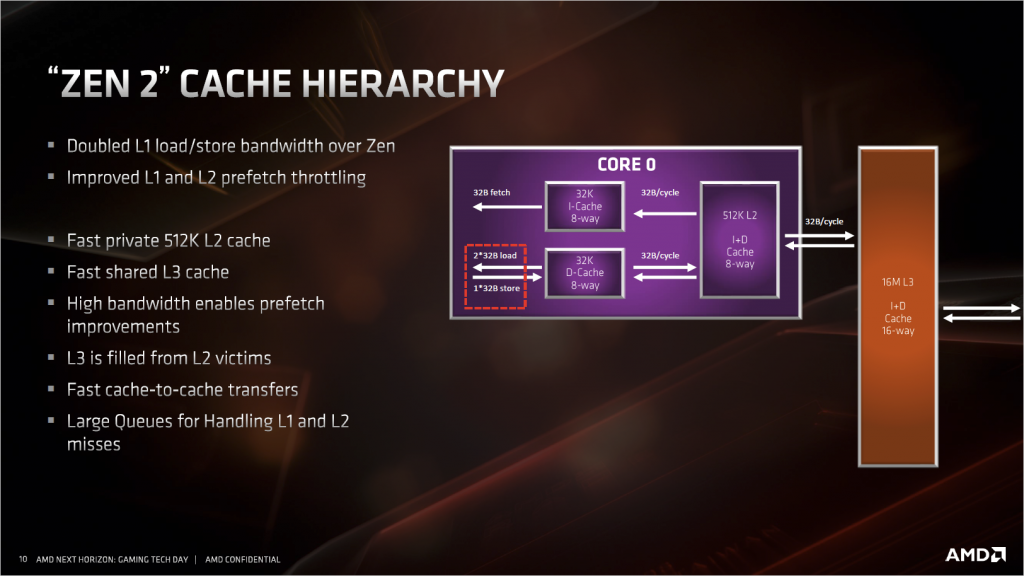
访存单元这次的改进主要是为了配合AGU和浮点单元的改进。LSU方面,因为AGU增加到了三个,所以LSU这里也要配合着变成每周期能接受2读1写的设定。浮点单元部分,SIMD的宽度加倍到了256bit,所以同样这里也要从原来的128bit读写变成256bit读写,对应到L1缓存上就是带宽加倍。
别的改进:存储队列长度加4。二级数据TLB加到2K entry,重要的是,增加了1G大页面的支持,这对于windows 操作系统来说意义不大,但是对于Linux操作系统来说,很多高性能库,软件和驱动,比如DPDK,Oracle什么的,都依赖于1G的大页面来减少TLB miss,意义不小。
然后放上AIDA64的缓存测试图:

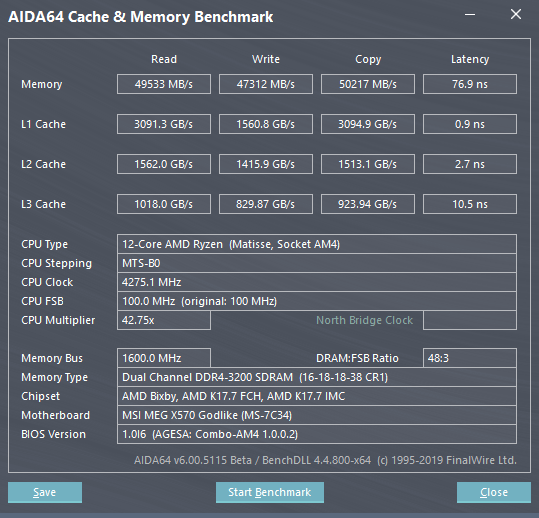
实测表明,L2缓存基本上单位频率,单位核心数下的带宽和之前保持一致。而L3应该不和CPU频率相同,实测中,排除核心数量的影响之后,可以看到L3的带宽快了一倍,这是因为3900x总计有4个CXX/4组L3,而1700X只有2个。
缓存延迟方面,AIDA64的这个测试太过粗略,所以换MemlatX64来看:
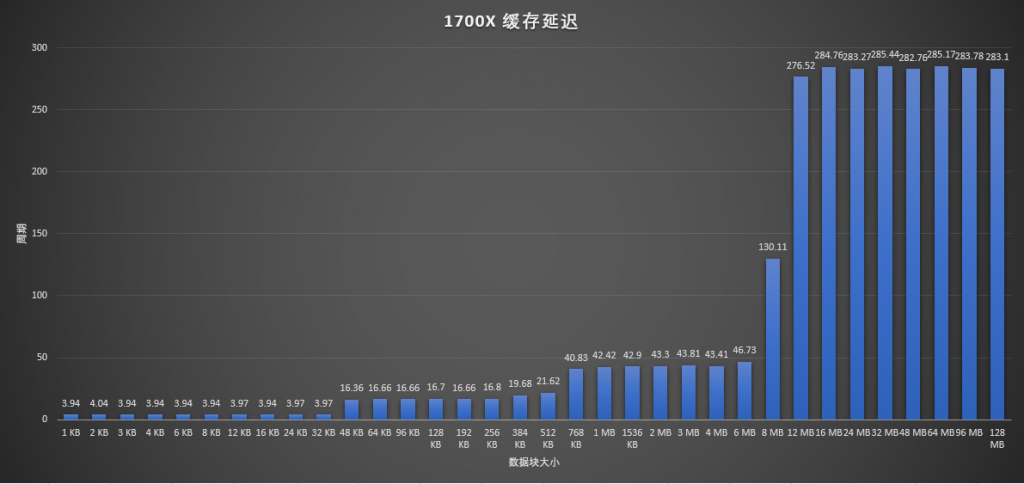
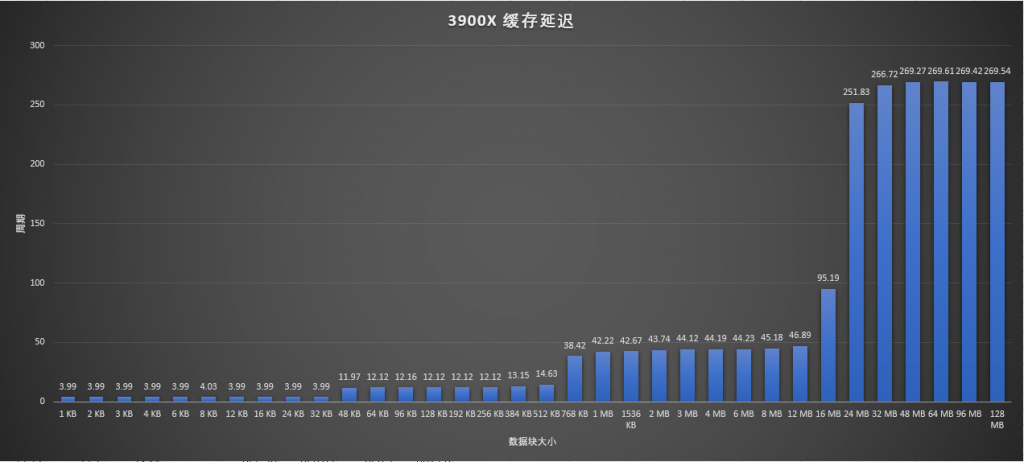
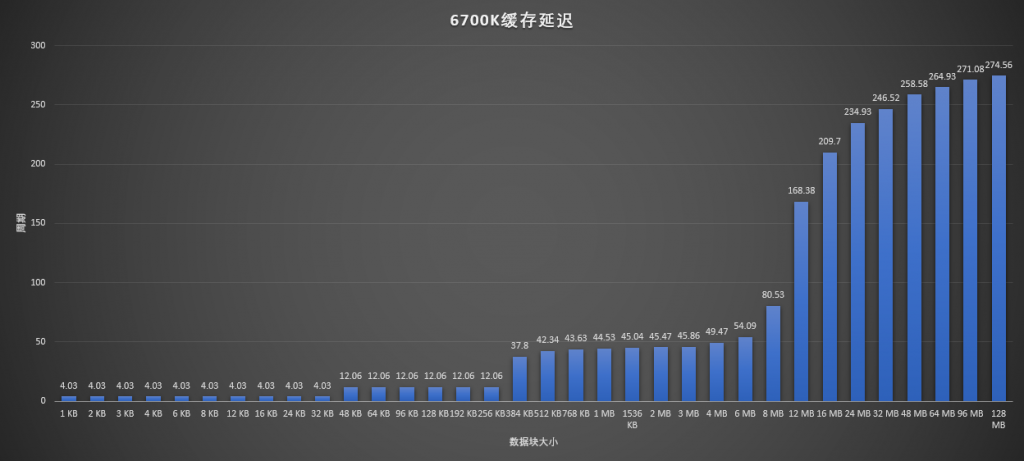
对比1700X和3900X,基本除了L2延迟和L3大小之外没什么不同的,L2延迟在Zen+中其实也已经改善过了,到了和3900X一样的12周期。对比一下3900X和6700K,可以看到各级缓存延迟其实都差不多,容量同样有点差别。但是过了L3缓存容量之后,有一个上升曲线,和AMD直接到顶不同。这是因为Skylake桌面版的L3依然是传统的缓存策略,会从内存预取数据。而AMD的是Victim缓存,L3里面的数据是从L2中最近刷掉的那些,并不直接从内存预取。
- 新指令

CLWB,这个是针对未来的非易失性内存而设计的,目的是清空所有缓存,避免关电的时候还有数据没有写回闪存中。
WBNOINVD,将缓存的数据写回内存,但不更改它为失效状态,失效状态意味着这段数据马上需要被替换掉,通常写回内存就意味着这段缓存不会再频繁使用了。下面举的例子可以说明他的作用,因为DMA只能访问内存,使用这个指令将缓存数据写回内存之后,CPU可以继续使用这段缓存中的数据,而DMA也可以正常的从内存中读取数据传输到别的设备。
QOS,就是字面意思,家里路由器的QOS感觉差不多,在高并发的环境中,给与需要的线程足够的资源来提高整体的吞吐率。
- CPU拓扑结构

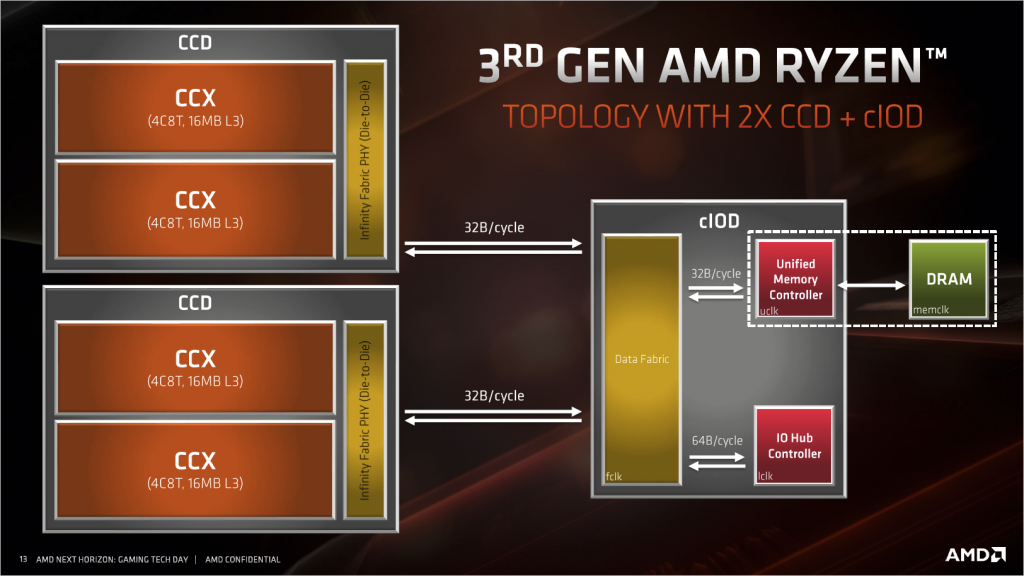
这次Ryzen的结构其实应该大家都清楚,八核及以下都是一个CPU die一个IO die,往上则是两个CPU die 一个IO die。所有内存和PCIe链接都是由IO die提供的,IO die没有区别,那么内存通道和PCIe数量就没有区别。带宽上,CCD与cIOD之间的带宽为32Byte/c,工作频率为FCLK频率,一般情况等于内存的实际工作频率(不是DDR频率),但实际可以自己以33Mhz为步进手动调整,在3200MHz的内存频率下带宽为51.2GByte/s。而cIOD内部,DF与内存控制器之间,带宽也是32Byte/c,工作频率为UCLK频率,这部分频率与内存直接挂钩,可以设定为1:1内存工作频率,也可以设为1:2内存工作频率,这种设定减小了内存跑高频时给内存控制器带来的压力,但我们计算一下,3200MHz的内存使用1:1的话,带宽刚好51.2GByte/c,和双通道内存带宽一致,而如果使用1:2的设定则只有实际内存的一半,基本上1:2模式除了可以把内存超高之外,毫无意义。
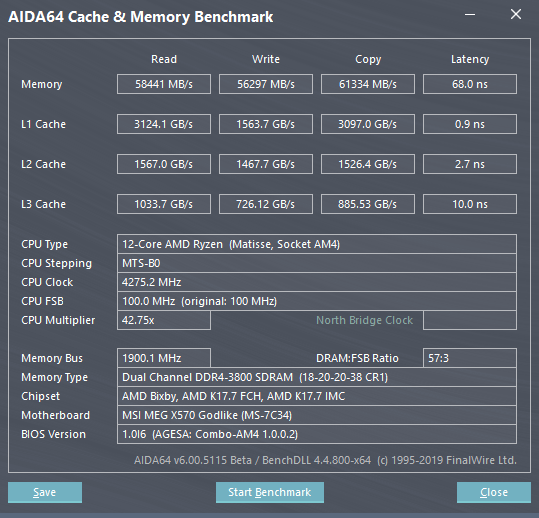
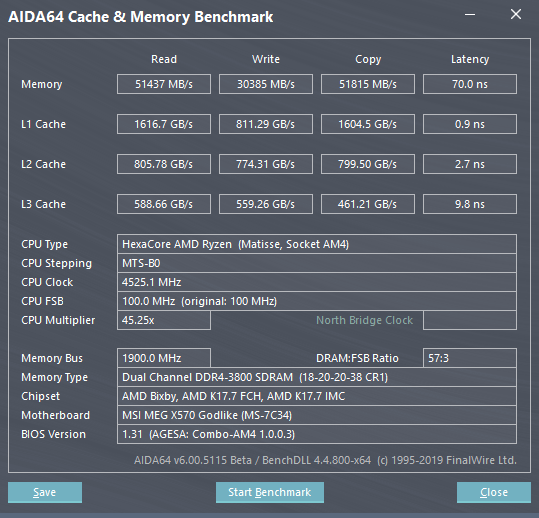
对于这种设计来说,包括我在内的很多人都认为,多了一个IO die内存延迟会差一点,甚至有人放言,Ryzen三代的内存延迟绝对低不过80ns。在之前的LSU介绍部分,我已经放出了3900X的AIDA64延迟测试截图,我们可以看到,延迟甚至比一代的低3ns,并且考虑到两者可以跑的内存频率,实际新一代Ryzen是在这点上是远远领先于1700X的。这里再上一张3900X加CJR的皇家戟3200MHz稳定运行在3800MHz的测试截图,这个频率是通过MSI的主板功能Memory try it直接设定的,非常轻松:
除开内存延迟之外,还有一个担忧,就是双CPU die的Ryzen会不会CCD之间的互联延迟比上一代Threadripper还高,毕竟Threadripper还是两个CPU die直接互联,而新Ryzen还要多经过一个IO die。为此我专门写了个小的乒乓测试程序,原理是两个绑定在不同核心上的线程互相对一个volatile属性的全局变量进行测试并改变,累计一定数量之后除以过程时间,得到延迟数据。为了减少测试量,我只是用了每个物理核心中的第一个SMT核心进行测试:
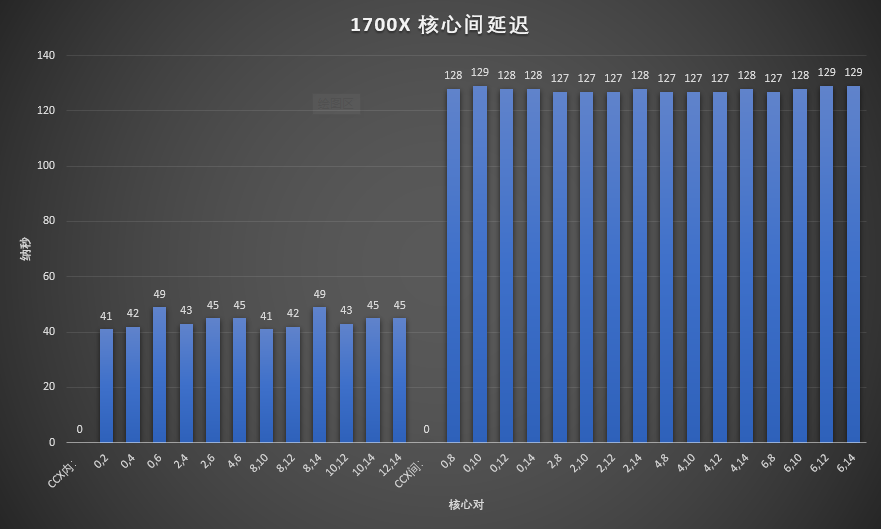
这里我们可以看到Zen1里面CCX内的核心之间互联延迟在41-49ns之间,而不同CCX中的核心间的延迟则要高的多,在127-129ns之间。
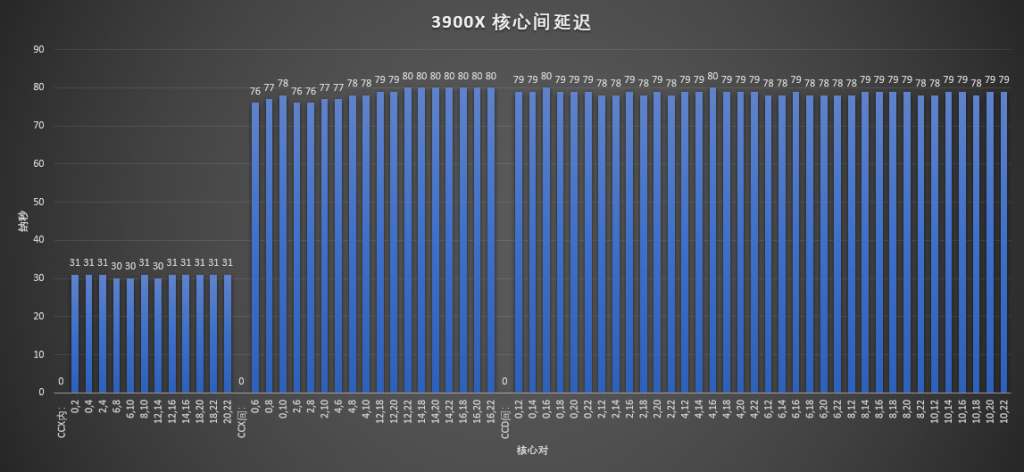
Zen2的 CCX内的核心之间延迟基本稳定在31ns,考虑到3900x的频率更高,这个结果也能理解。而不同CCX的核心之间延迟则大幅度下降了近40%,范围在76到80ns,可以确定CCX之间的Data fabric有了重大改进。再看看我最关心的CCD之间的延迟,竟然只有78-80ns,和CCX之间的延迟几乎相当,非常的难以置信,我完全想不到AMD是怎么做到,难道因为CPU die之间还有直接的互联?
为了验证这个想法,我想起朋友老六还有一颗1900X,所以让老六帮我测了一下1900X的 ,请看上面1900X的图
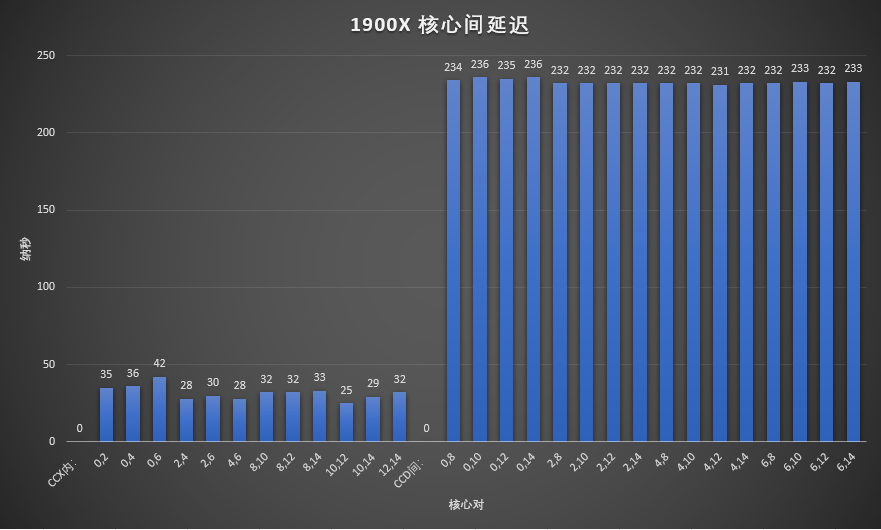
1900X每个核心只有一个CCX打开,所以就没有CCX之间的延迟这个说法了。CCX内,因为频率也较高的关系,所以看起来不错,但不是特别稳定。我们关心的CCD之间延迟高达230+ns,比1700X的CCX间延迟还几乎高了一倍,所以可以得出结论,即便Die直连也会有巨大的延迟开销,那么3900X的CCD延迟是如何做到的就成了一个迷,期待今年Hotchips中AMD的演讲。
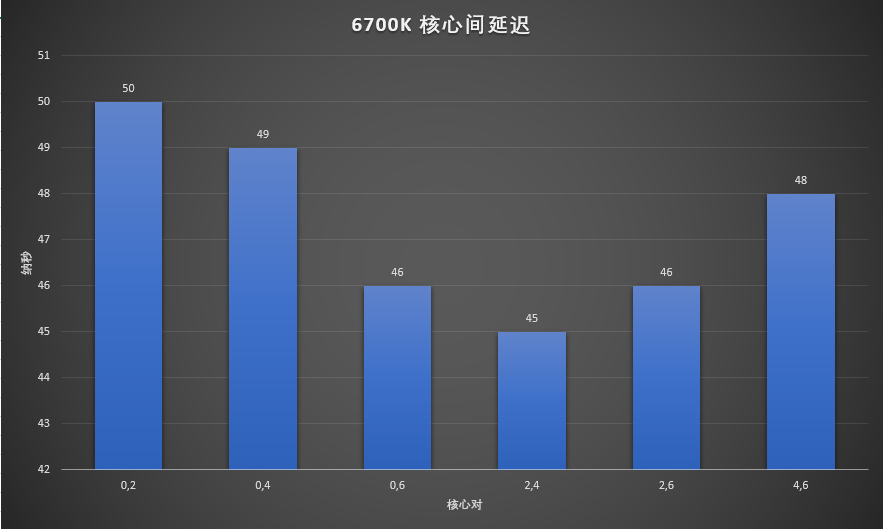
既然AMD的HEDT都有了,那么Intel的也搞一个:
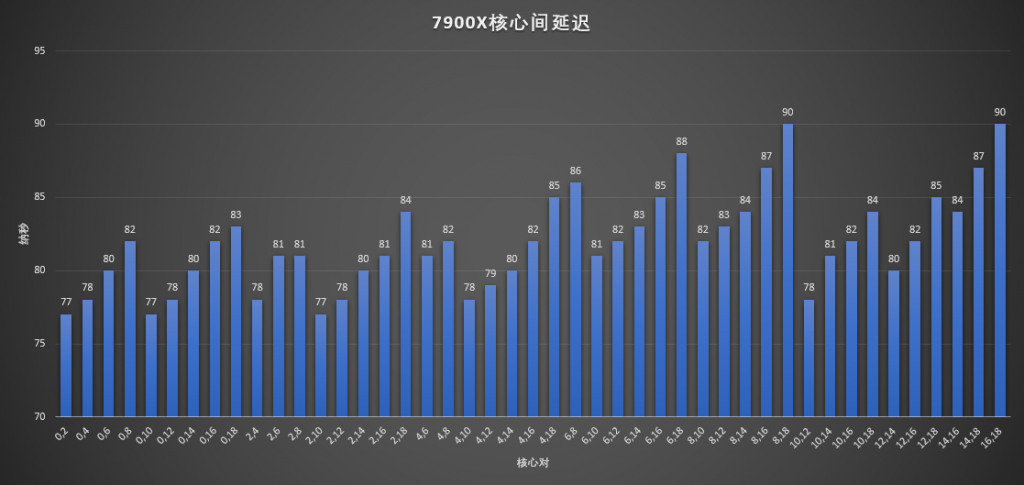
在Mesh的帮助下,延迟基本随着核心的距离变化而变化,所有延迟在77到90之间,比较稳定,如果和1900X比的话,无疑是相当棒的,不过在Zen2那个神奇的延迟面前还是有点失色了。
最后6700K Ringbus嘛,没啥好说的。总之这个测试的收获就是,不用担心多个CCD的处理器带来什么延迟问题了,想买几核买几核,只要钱够。
再稍微看下核心互联延迟与内存频率的关系:
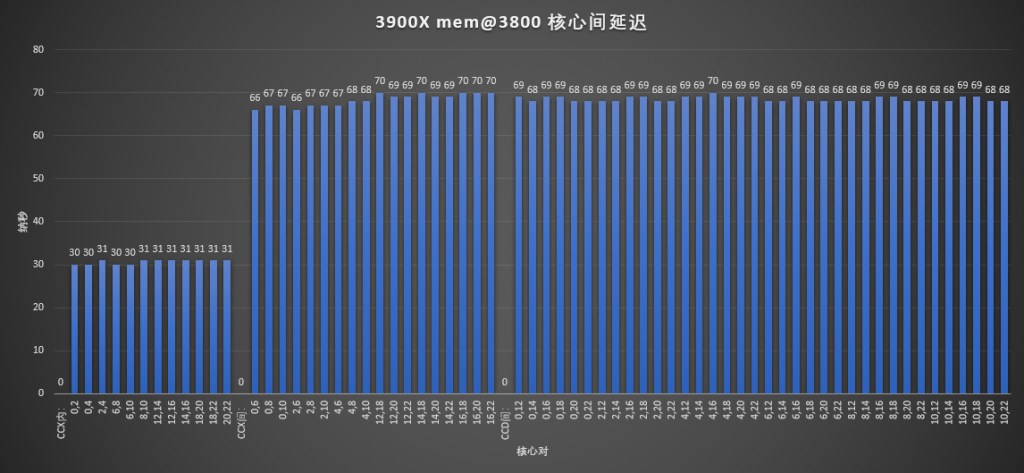
在3800的内存频率下,CCX内的延迟基本没有变化,但CCX间和CCD间的延迟下降了大约10ns,这是因为IF频率在内存频率提高时,也同步提高的原因。
单CCD问题,先看图:
这是3900X关掉一个CCD之后的内存带宽测试。可以看到内存读写速度都受到了不小的影响,读取速度还行,只低了几个G,但是写入速度跌了几乎一半。目前AMD还没有给出一个合理的解释。目前我猜测有两个原因,一是AIDA64有bug,二是AMD本来设计就是如此,IF上下行带宽不对等,32Byte/c的上行,但只有16Byte/c的下行。
更新:目前AMD已经确认,确实IF上行32Byte/c,下行16Byte/c,原因是AMD认为在桌面平台,写入带宽不那么重要,减少一点可以节约电力和面积。
最后其实还有一个担心,就是双通道内存,对于3900X的12核心甚至之后3950X的16核心来说到底够不够。这个问题比较难以回答,因为不同程序对于内存带宽的需求都是不一样的,所以建议如果有条件,可以试试自己用AMD(uProf)或者Intel(vTune)的免费profile工具测一下自己的用的软件,是不是性能是内存带宽导向的,如果是的话可以不用买那么多核心的处理器,或者是上更多内存通道的HEDT平台。