Zen2架构介绍:
在AMD翻身之作Zen1出来之后的第二年AMD又推出了它的改进版Zen2。这次的架构虽然说是改进版,但是比起AMD以往架构的各种改进版来说,改进幅度相当的大,甚至大于K8到K10的幅度。下面我就简单的来介绍一下这次的具体改进。
- 取指部分(Fetch)
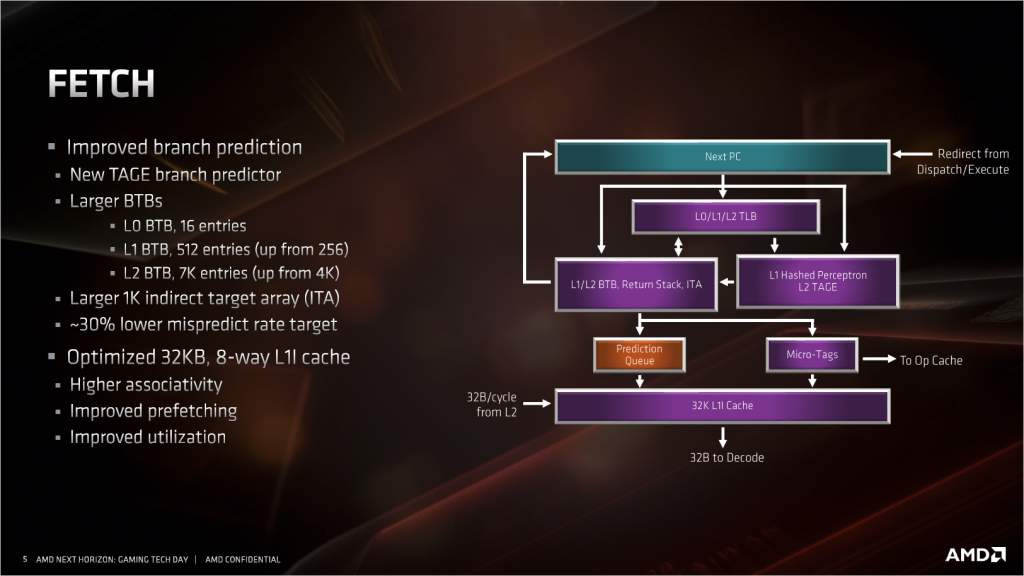
这部分最大的改进是,把原来的两级神经网络分支预测器的第二级,换成了新的TAGE分支预测器。说起原来的神经网络分支预测器,其实挺有意思的,按传统的分支预测器其实就是个单层的感知机,即便是推土机上的分支预测器要说成是神经网络分支预测器也是没问题的,所以Zen1的时候AMD用那个叫法其实是耍了个小聪明,蹭了个热点。新的TAGE分支预测器全名叫TAgged GEometric length predictor(标记几何长度分支预测器),差不多是目前最先进的分支预测器实现,这个分支预测器的逻辑很复杂,够写几页论文的,这里就不多做介绍了。
除开分支预测的改进之外,L1I的也有不少变化,虽然容量从64KiB减少到32KiB,但组相关从4路增加到8路,其实从理论上来看,很难说这种改进是有益还是有害的,不过AMD敢这么改,应该是经过仔细权衡的。L1I的带宽是AMD的传统强项,32Byte/cycle对Intel的16Byte/ cycle 。
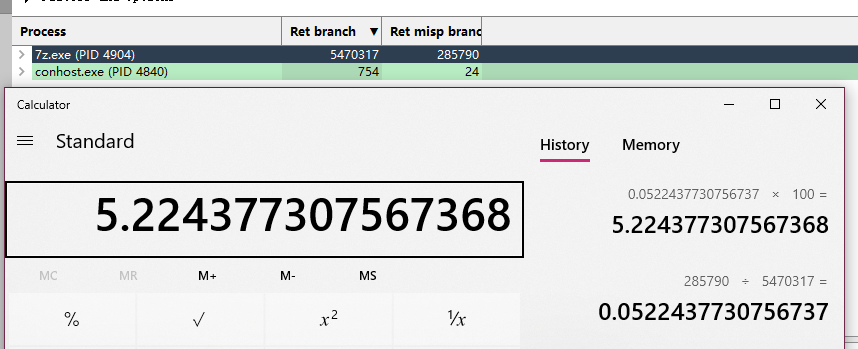
7月7日AMD针对Ryzen 3000系列更新了uProf profiling软件。这里我用它来测试一下Zen2的新分支预测器改进。测试方法很简单,在工具中获取执行完毕的分支指令采样数和执行完毕的预测失败的分支指令采样数,算下比例即可。这里我使用7z压缩软件以单线程模式压缩同一个文件来进行测试,以下是结果:
3900X:
1700X:
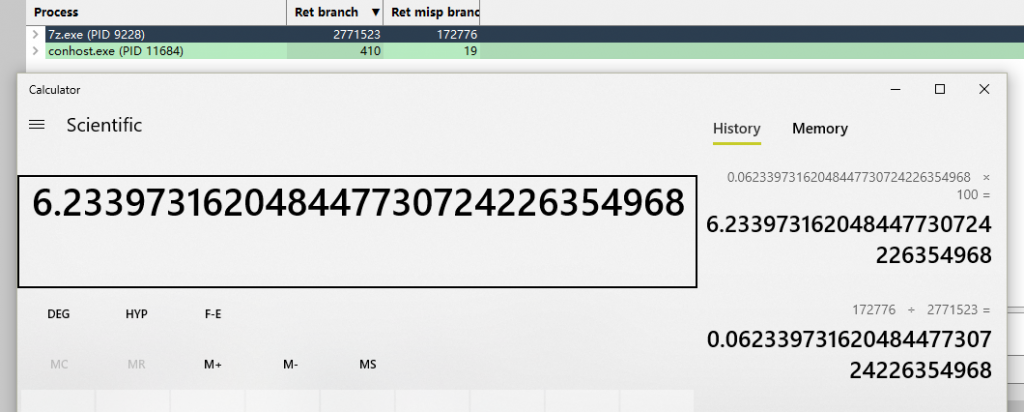
有大约1%的失败率降低,这对于现在本身失败率就很低的处理器来说,是个不小的提升。
- 解码部分(Decode)
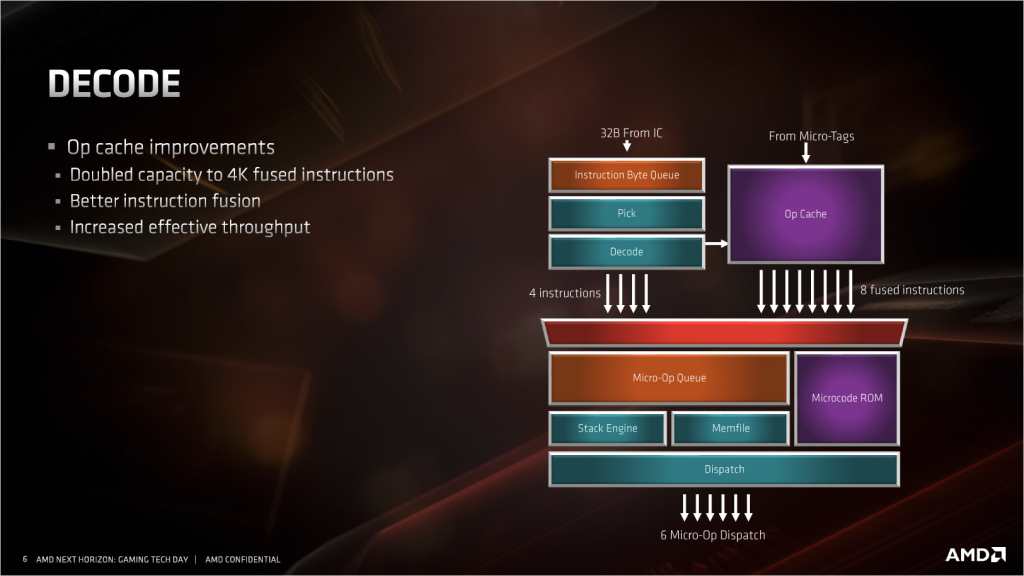
解码器本体没有什么变化,依然是4条指令每周期的带宽。这部分主要是把微指令缓存(Ops cache)的容量翻倍了,这样可以缓存更大的代码块,对于复杂的函数和循环来说很有帮助。Ops cache是用来缓存解码器解码出来的宏指令(Macro op)的,一来为后面的乱序核心提供更高的宏指令带宽,二来减少了解码器(Decoder)的工作,避免在解码器上消耗过多的电力,最后还顺带减少了等效的流水线级数,避免过高的分支预测失败惩罚。Intel的处理器也有一个对应的 μop cache,功能也相同,不过仅仅只有6 μops/c的带宽,低于AMD这边的8 Macro ops/c,容量上只有1536个 μops,远远低于Zen2的4096。 实际 μop的比Macro op更简单,X86指令解码出来的 μops也比Macro ops多,Intel的 μop cache容量就显得更小了。
Macro op:K5开始AMD为了性能引入更先进的精简指令集(RISC)内核(其实就是自家的RISC处理器Am29000)。这个精简指令集的内核有一套自己的指令集,在X86处理器中,AMD将他称为RISC86,RISC86指令也就是我们所说的Macro op。X86指令进入解码器之后,解码器就会将他翻译为一个或者多个Macro op。
Micro op:Macro ops依然不是直接可以直接给硬件执行单元执行的指令,硬件执行单元需要更细的指令,比如需要访问内存中数据来作为操作数的加法Macro op,那么我们需要让这个Macro op生成一条控制加法器的指令,一条控制访存单元(LSU)的指令,生成的这些指令就是Micro op。一条Macro op可以翻译为一到多条Micro ops。
μop :Intel同样为了高性能引入了RISC内核,但Intel直接将X86指令解释为类似AMD的Micro op的东西,Intel将他称为μop。
指令融合改进,细节AMD没说,总之能改善整体吞吐率就是了。
指令融合:分为宏融合(Macro fusion)和微融合(Micro fusion)。宏融合就是把两条连续的X86指令视为一条,整体进行解码,执行。微融合是Intel独有的,因为Intel没有Macro op这一说,而是直接解码成更简单更多的μop,导致解码器到执行单元的有效带宽不足,所以Intel不得不把多个过于简单的μops,组合成一个更复杂的fused μop来节约带宽,这就叫Micro fusion,之后快到执行单元之前再解开组合。
在有了uProf之后,这里同样加入一个Ops cache效率测试,测试内容为,处理器Decoder给出的Macro ops和Ops cache给出的Macro Ops比例:
3900X:
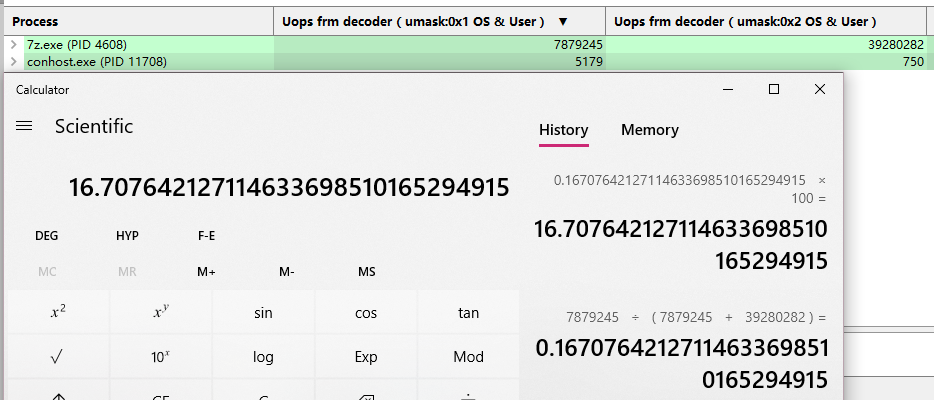
1700X:
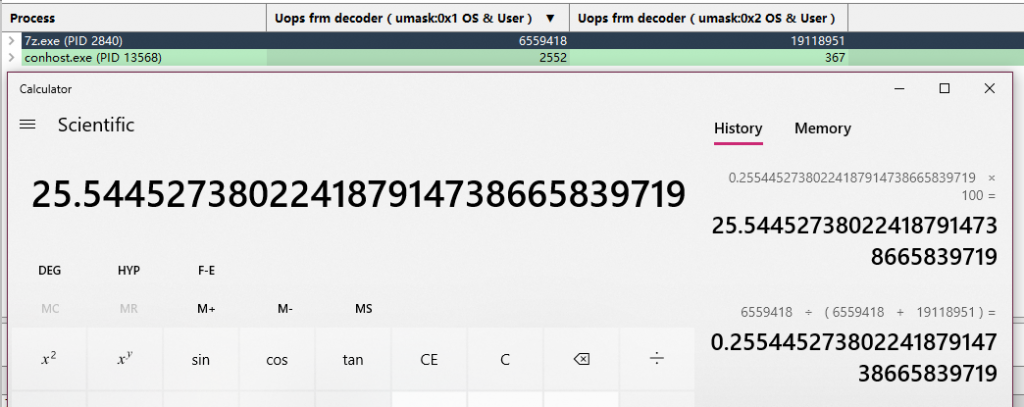
翻倍的Ops cache容量同样带来了近10%进步,非常不错。
- 浮点执行单元(FPU)

AMD的Zen1,之前最被人黑的一点就是这里。Zen1的的FPU由4个128bit的SIMD单元构成,一般浮点运算,可以支持4*128bit的AVX/SSE或者2*256bit的AVX并行,这一点上和隔壁Intel相比其实没有任何劣势,甚至在128bit指令的执行上有一倍的优势。但是在FMA指令上,只有2*128bit或者1*256bit,因为FMA是由加法和乘法SIMD拼接完成的,并不像Intel的2*256bit是独立的单元,结果就是在各种测试浮点单元理论吞吐率的软件中被Intel大幅领先。
另外一点,这里FPU虽然名义上的浮点单元,但整数SIMD指令也是在这里完成的。针对整数的AVX2指令,AMD当时可能考虑应用没那么广泛,所以没有设计太多的执行单元,导致被Intel吊打。
在Zen2架构中,AMD应该看到了这些劣势,所以把所有SIMD单元的宽度都直接加倍,现在有4*256bit SIMD,两个浮点加法SIMD和两个浮点乘法SIMD。上面提到对Intel一倍优势的128bit指令,优势保持不变,在256bit的AVX指令上,现在也有了一倍的优势,FMA指令虽然也是拼接完成,但得益于暴力的SIMD宽度翻倍,性能和Intel家的也能持平了,形成了最差我也不会输,一般情况吊打你一倍的优势局面。
AVX2方面Zen2同样也基本做了翻倍处理,基本上除开饱和算术指令之外,别的都能达到或者超过intel的水平,可以说互有胜负。
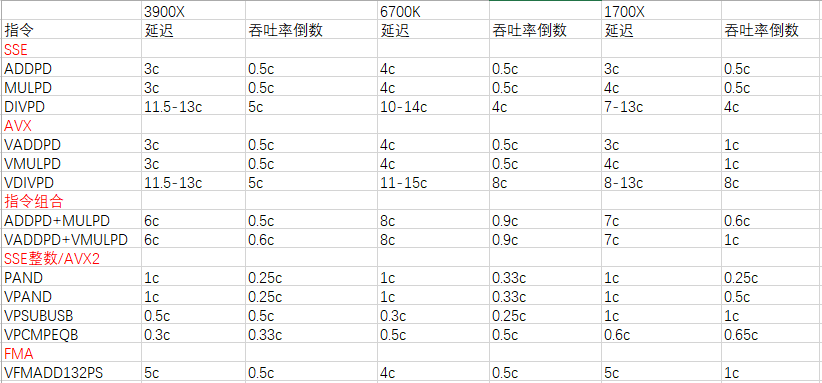
这里我是用InstlatX64测了一点点数据,给大家看看(测试中使用的CPU为了得到稳定的结果,都使用定频模式。结果以周期为单位,频率高低并没有影响。数值越低越好):
- 整数单元(IEU)
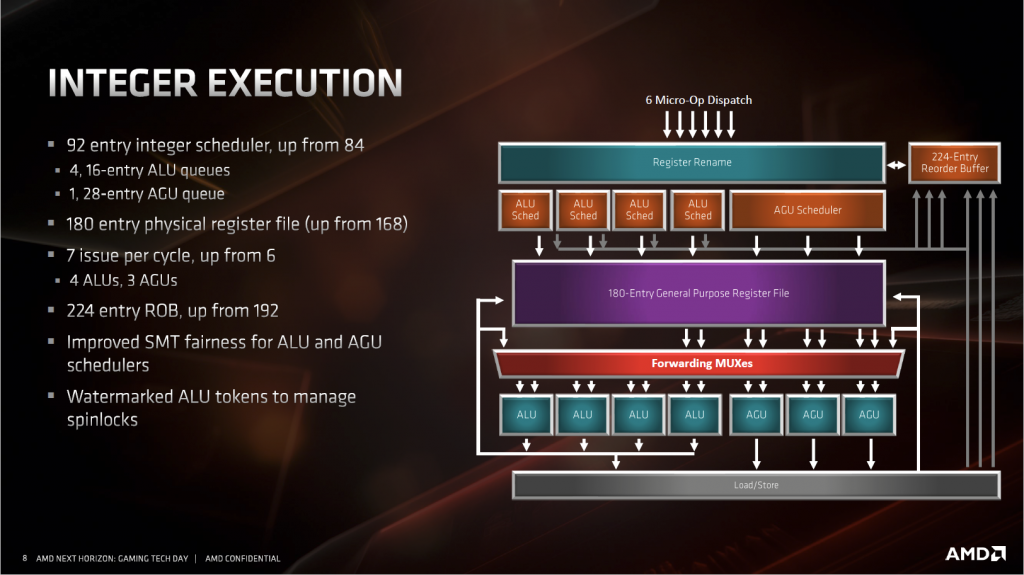
重排序缓冲区(ROB,Reorder Buffer):它的大小决定了最多能从多少指令中来提取可以并行的部分。
物理寄存器堆(PRF,Physical register file):它的大小则决定了这些提取出来的可并行的指令可以使用多少重命名的寄存器。
保留站(RS):则是这些指令等待乱序发射的队列。
整数单元的性能主要看指令级并行能开发到什么程度。AMD在Zen2中将上面说的每一个部件都进行了扩充,期望获得更高的IPC。 这些部件的提升幅度和Intel这边Haswell到Skylake几乎完全一致。
除开这几样,AMD在访存方面也做了加强。增加了一个AGU和它对应的发射端。Zen1中的只有两个AGU,所以Zen1最多只能做到两读或者一读一写,这对于IPC来说是不利的。大部分指令通常需要两个数据来源,然后产生一个结果。两AGU在前一条指令写结果的时候,只能读取一条数据来源,然后额外消费一个周期来读取另一个来源,再下一个周期ALU才能开始执行运算,中间就多了一个空闲的周期。三个AGU就不同了,前一条指令回写结果的同时,可以同时读取下一条指令所需的两个数据,再下一个周期ALU就可以直接进行运算了,节约了一个周期,所以AMD改到3 AGU非常的合理。
AIDA64有个测试ROB大小的工具,所以姑且一测下ROB的大小(其实没什么好测的,官方一般这种地方不可能乱说):
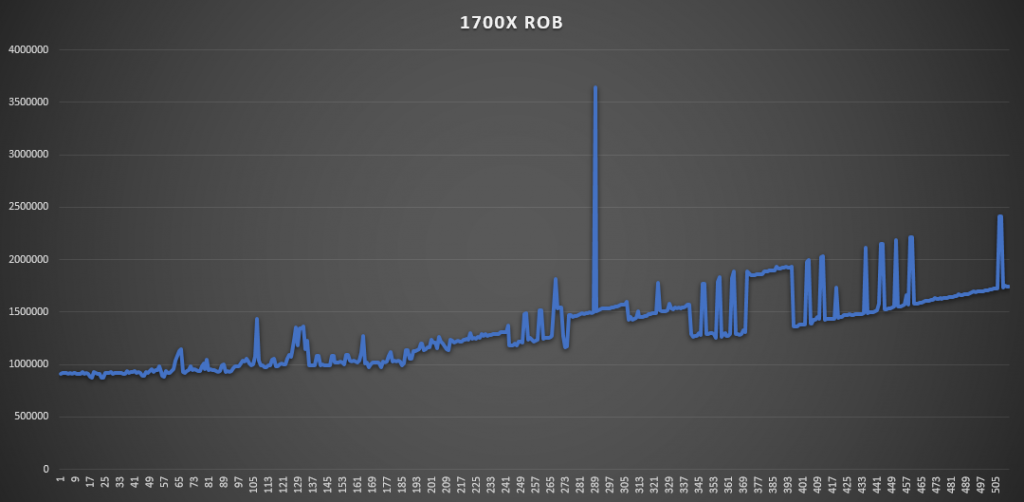
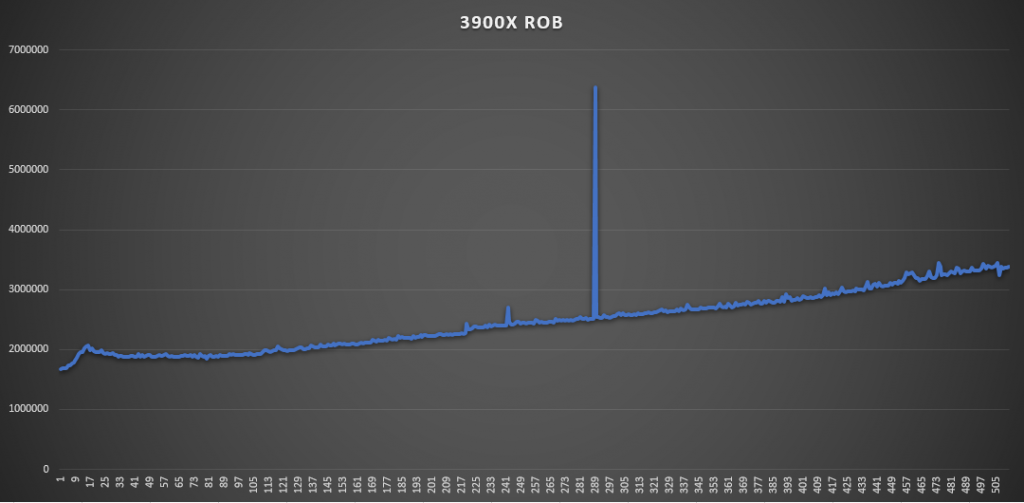
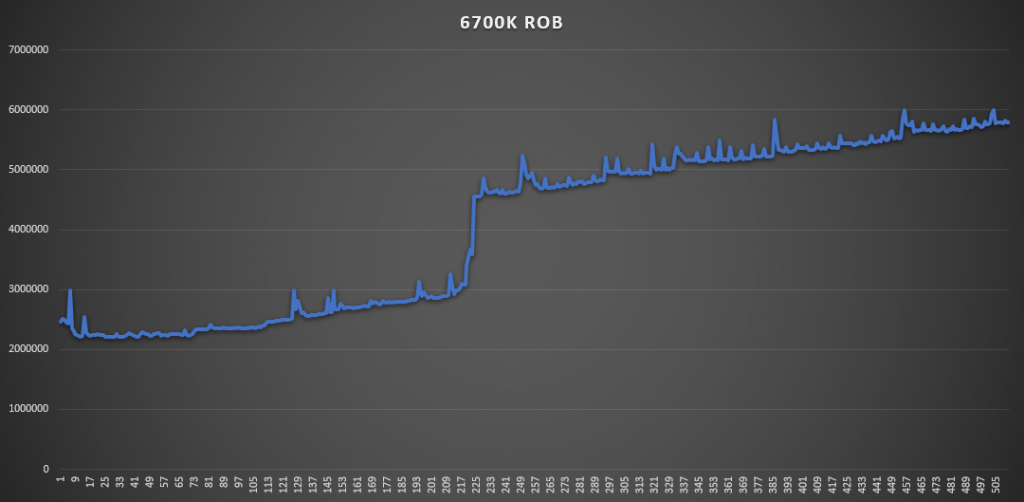
出于好奇心顺带测一下Zen2的乱序核心的峰值吞吐率,因为现在AMD的uProf profile工具还不支持Zen2,所以测试是我现写的,基本就是各种指令跑循环,用循环次数,每次循环的指令数,频率和时间来算IPC。循环中的指令和循环长度需要自己慢慢调整来达到一个最佳值:(结果不考虑Macro fusion的情况,所有满足Macro fusion的指令组合都被视为一条)
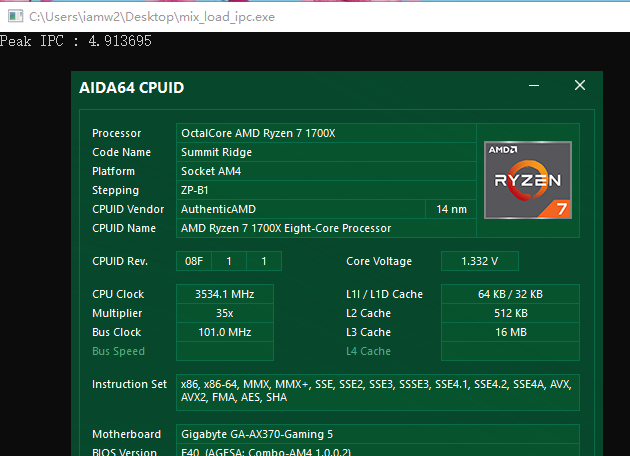
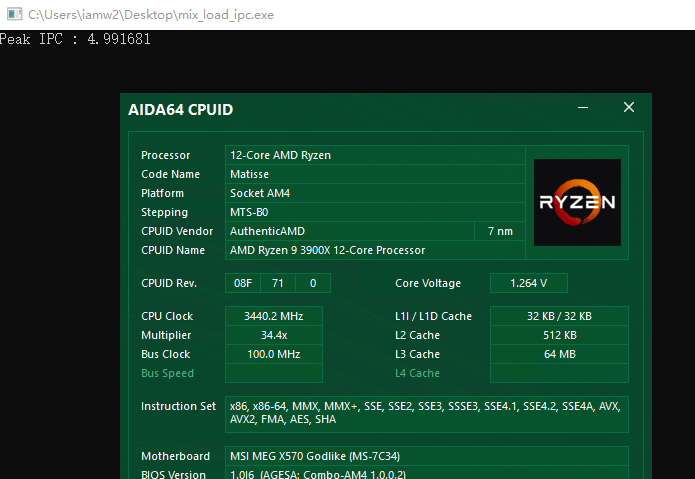
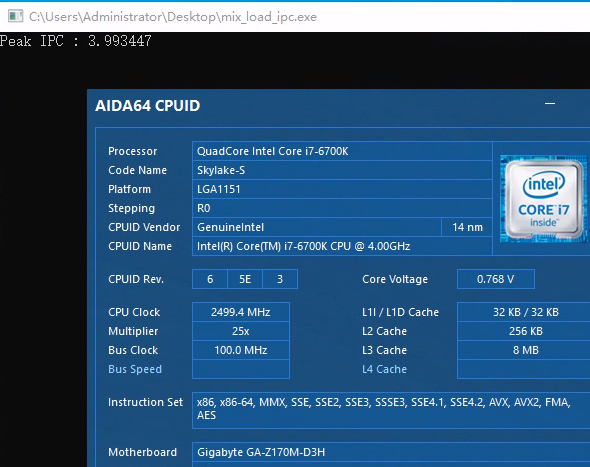
因为现在的处理器频率调节技术都很先进,所以即便手工定频结果会有一些误差。基本上Zen1和Zen2没有区别,峰值都能跑到5,算是不折不扣的5发射处理器,按理论来看其实应该有6,考虑到前端和ROB带宽都没有瓶颈的情况下,可能是别的部分有了什么限制。Intel的Skylake,则是因为Retire的带宽最多只能到4,所以IPC也只能到4了。之前网上传言Skylake能5发射,我想是考虑了Macro fusion的情况,当然这个在早年间Intel的处理器上就能做到,不是Skylake独有,并不稀奇,而排除Macro fusion后,第一款真5发射X86处理器的头衔,我想应该给到Zen1的头上。