超采样
计算机图形中的光栅化是把一系列3D空间图元转换为2D图像的技术。对于多边形的光栅化,2D图像中的每个像素点中心会有一个采样点,如果有图元覆盖了该采样点,像素便会被设置为该图元的颜色。
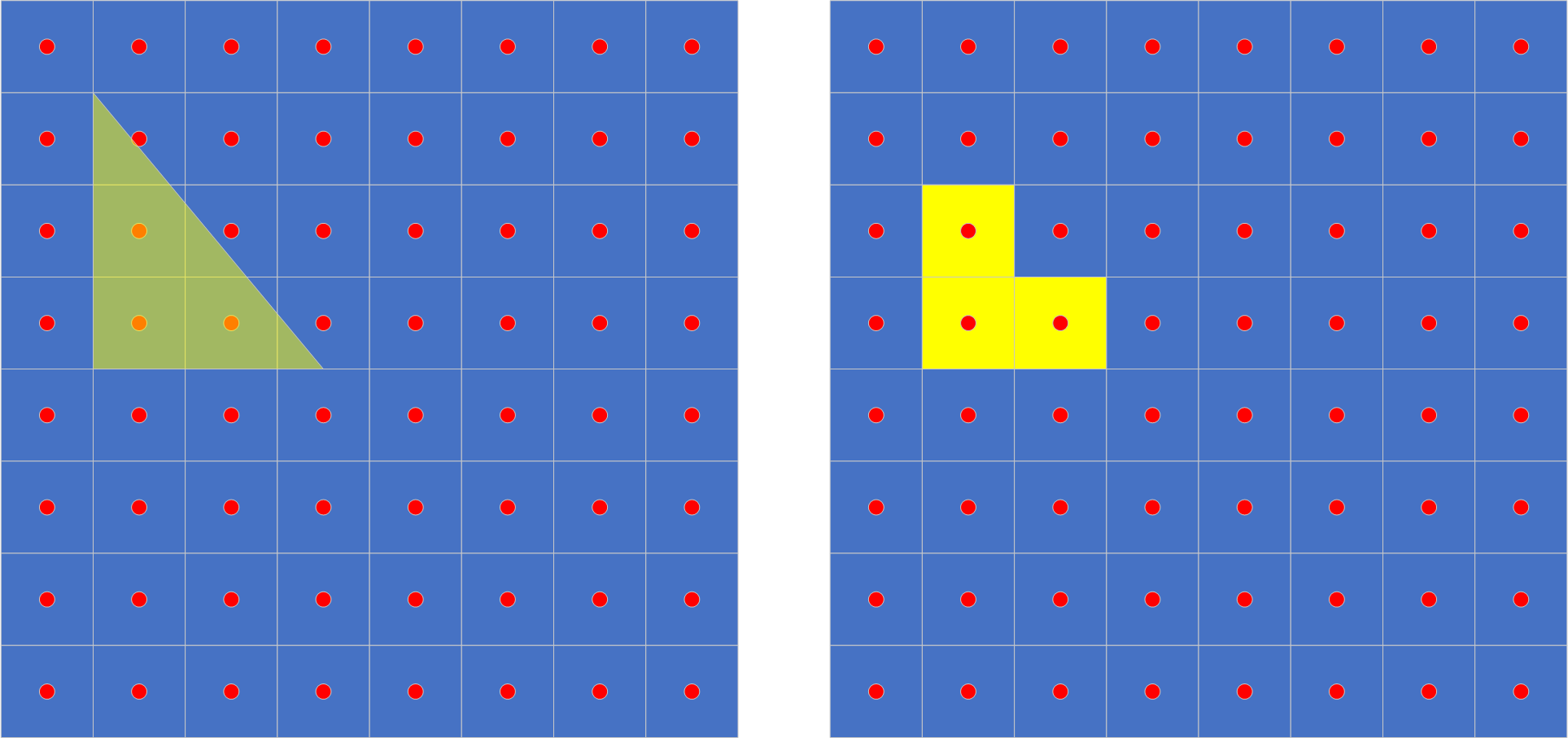
从上图我们可以发现,像素是一个具有面积的正方形,而采样点只有一个点,所以即便该三角形覆盖了的像素点,只要他没有覆盖到该像素点的采样点,该像素点的颜色依然不会发生变化;而有些像素即便只有部分覆盖了三角形,却依然获取了该三角形全部颜色。
由于没有过渡色,这就带来了一个糟糕的后果,图形的显示会产生锯齿感。为了缓解锯齿感,可以使用高分辨率来渲染和输出,也可以在一个像素中使用多个采样点采集颜色并混合,但归根到底都需要使用更多的采样点。
上图中第二行就是增加采样点之后的结果,第二幅为直接输出的结果,第三幅为混合之后低分变率输出的结果,可以看到两者的锯齿感都平滑了不少。
不过我们仔细观察结果可以发现,形状和原本的形状并不符合,原本的斜三角形,变成了正三角形。对于这种情况我们可以通过改变采样点的位置来达到更好的效果。

这下可以很好的体现出三角形的形状了。通常我们都用Halton序列来安排采样点位置,以求更好的均匀度。当然总体来说,更多的采样点才是正道。
多帧超分辨率
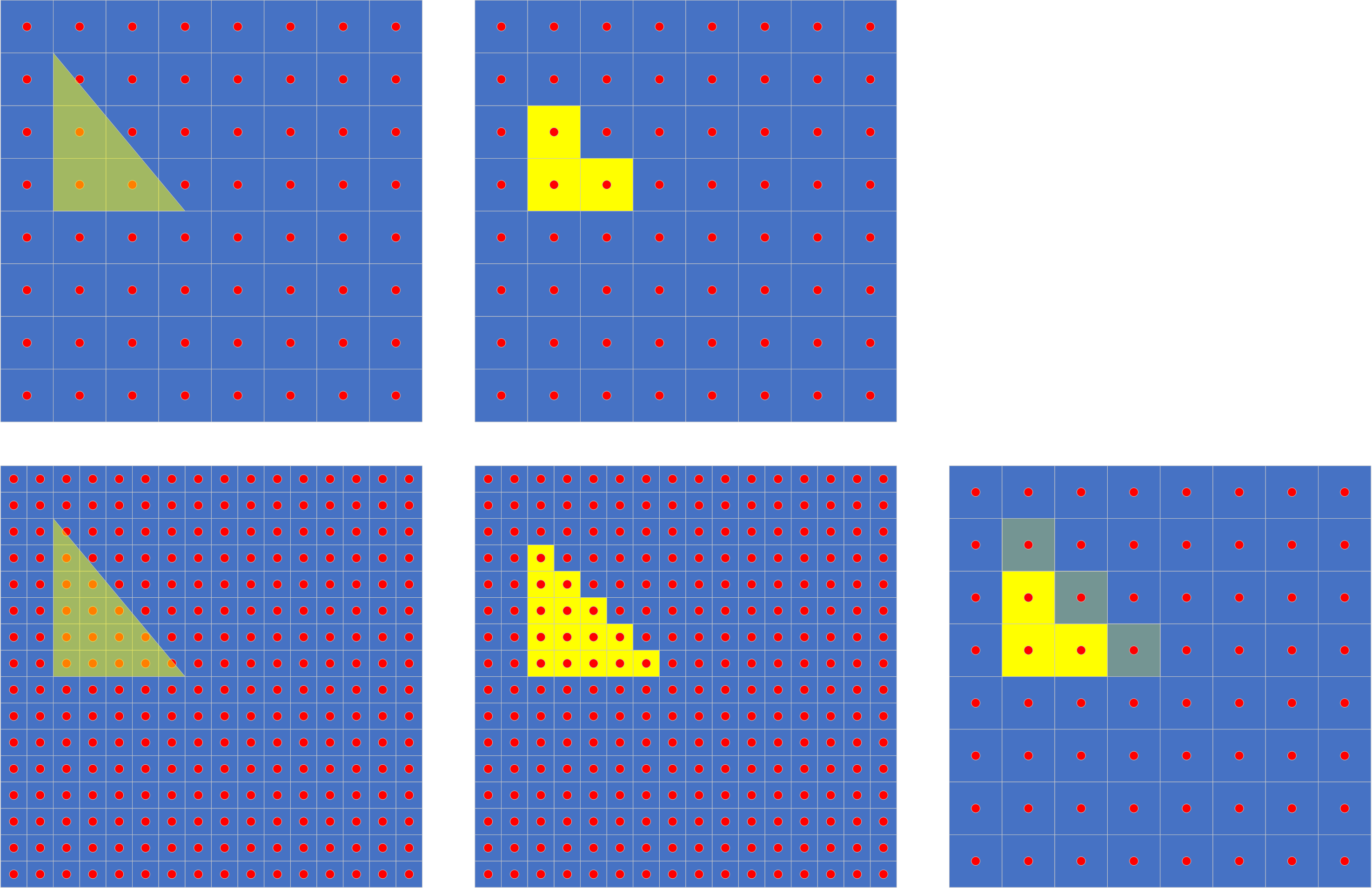
以上的例子中,采样点都来自同一帧。我们也可以从多帧画面中来获取更多的采样点。

我们可以看到,第一排代表N-1帧,我们只从左上和右下取样;第二排代表第N帧,我们只从左下和右上取样。高分辨率输出需要将两帧图像交错组合,低分变率输出则因为画面不停的变换,最终抖动形成的图形,结果就如第三排,可以看到和从单帧中使用双倍采样点形成的图像一致,但是因为每帧的采样点减少,性能可以提升非常多。高分辨率输出图像的这种方法,就是游戏机中常用的棋盘渲染,而混合后低分变率输出的方法则是ATI的Temporal AA和Nvidia的MFAA。
这种方法因为只依赖于前后两帧的图像,在帧率较高的情况下,即便有物体移动或者镜头移动,也不会有太差的效果。
如果我们从更多帧中取样的话,就需要考虑更多的问题了。
首先,不能依赖于抖动了,毕竟太多帧,人眼的视觉残留没有那么长,需要混合历史帧和当前帧来生成图像让肉眼看到。
第二,需要保留每一帧采集到的图像吗?保留太多图像会占用大量的显存,读取写入这些图像也需要太多的带宽,所以怎么办?其实只需要保留上一帧混合好的图像就可以了,通过改变混合时候的比例,就可以控制历史采样点的生存周期。

第三点,像素的位置变化了怎么办?这个问题很容易,我们为每一个像素都生成一个运动向量,这样我们就知道当前位置的像素,在过去对应着哪个像素,我们再使用对应的历史像素就可以了。
那么运动向量怎么生成喃?我们要考虑两个方面,一个是视角的运动,一个是3D物体的运动。对于视角运动,通常从相机矩阵的变化中就可以得到。对于物体运动,可以从各种几何相关的渲染阶段得到,但运动向量的生成远不止表面看到的这么简单,比如动态的纹理,比如无规则的物体运动,比如透明的物体。
上面们只考虑最简单的情况,每像素点都有与其它时刻对应的像素点。但实际应用中,会有缩放,有图形出现,有图形被遮挡或者消失。
对于缩放,缩小的话,我们可以使用周围像素点来混合出一个新的像素点,对于放大的话,我们可以插值出新的像素点。
而对于图形的出现,我们需要确认哪些像素是新出现的,如何确认喃?我们可以通过对应的3D物体的ID,3D物体的深度,3D物体的法向量,甚至过大的颜色变化来确定,然后再调整alpha来将历史帧数据快速的抛弃掉。
完成以上三点之后,如果我们按高分辨率输出图像,那么我们就实现了传说中的TAAU,如果我们按原始渲染分辨率输出,那么我们就得到了最简单的TAA反锯齿。
当然这些只是最基本的,还有很多改进需要做。比如前面提到的运动向量不可靠。对于这一点,我们没办法让他变的更可靠,那么我们就需要尽量处理掉他造成的后果。一般来说,会使用颜色裁剪和钳制来处理,简单的说,就是前后帧色彩差异过大的时候,使用采样点周围的色彩形成一个色域上的包围盒,如果历史帧色彩超出了范围,则在包围盒边缘上取最接近历史色彩和当前采样点色彩的点,作为历史像素的色彩。
显而易见的,这样做会造成一些高频细节被抹得平滑起来,简单来说,就是糊成一片。
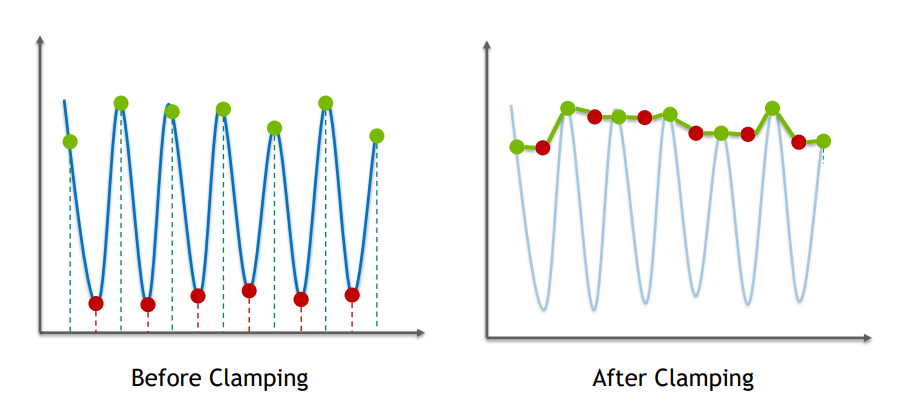
这也是为什么,玩家对TAA和TAAU的评价这么一致的原因。
神经网络兴起之后,给了这个问题的一个解决方法。通过神经网络训练来解决TAAU中的裁剪和钳制的问题,不再使用粗暴的方法将色彩直接加以限制,让正确的采样点色彩得到保留。
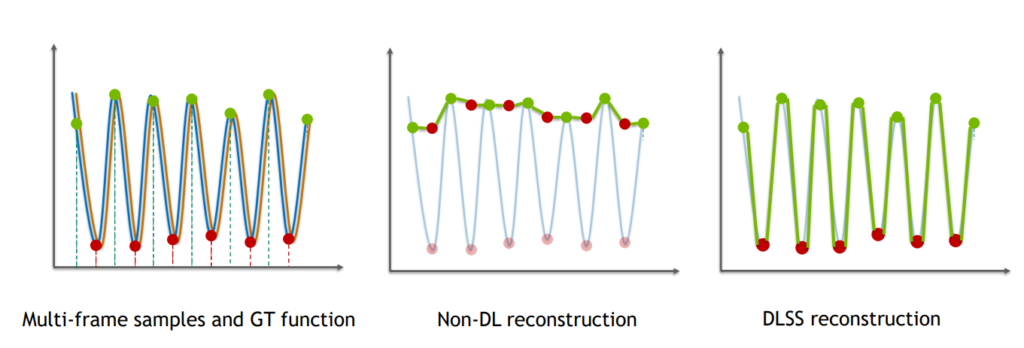
虽然最终依然有一些偏差,但是效果远好于TAAU。和原生高分辨率图像,相差无几。这便是DLSS2。
所以我们可以看到,DLSS2其实就是神经网络辅助下的TAAU。当然背后还有很多细节,比如图像稳定性等等的问题,这个文章只是科普就不多说了。
关于DLSS2有一个广泛流传的说法,就是DLSS2可以依赖于AI来生成本不存在的纹理细节。这个说法,一部分正确一部分错误。
错误嘛,其实看到这里,我们已经知道无论TAA还是DLSS2,都没有对纹理进行任何处理,更不用说脑补细节之类的。而且我们都已经知道无论TAAU还是DLSS2都是在低分变率下进行渲染的,低分变率下对应纹理MipMap的LOD值和高分辨率下是不同的,分辨率要低一些,所以在使用TAAU和DLSS2时,我们需要给LOD加上一个负偏移,让它和高分辨率渲染时的分辨率相同,这样纹理才不会模糊。
正确的地方,纹理确实更加清晰了,为什么喃,很简单,比如TAAU在1080p下渲染,输出分辨率4K,像素量差了4倍,但是不同位置采样点的数量可能大于4倍,这样纹理就会有更多细节被还原出来,这些细节都是纹理真实的细节,而不是脑补的。
单帧超分辨率
单帧超分辨率,其实就是单纯的将图像放大,这种技术很多,比如双线性插值,比如Lanczos,比如AI支持SRGAN等等。
单帧超分辨率因为样本就只有输入的那些像素点,所以提升分辨率时所需的信息比较有限。
FSR就是这类技术之一,FSR使用常见的Lanczos2算法进行图像缩放,这是一种很常见的图像缩放算法,基本质量好一点的视频播放器或者图片查看软件上都有应用。Lanczos算法的优点在于简单,资源消耗小,缩放效果好,图型边缘会看起来更锐利。但它的缺点是,在图形边缘会留下鬼环,一种围绕图型的深浅相间的窄圈。所以FSR在这里加了一个色彩钳制,让边缘的色彩平滑,去掉了鬼环。之后又加上了CAS,对放大后的图像进行了锐化,降低模糊感。并且原始图像的质量越高,效果也就越好,所以FSR也需要一个纹理上的负LOD偏移,当然FSR之前的反锯齿也是影响质量的关键,而别的引入噪点效果则需要在FSR之后再添加。总体上来看,它是一种很稳定,质量也很不错的算法,在原始图像质量较高的时候,几乎可以达到以假乱真的效果。
DLSS1同样也是这类算法,只是使用AI来助推,DLSS1同样分为两个步骤。它的第一个步骤是AI反锯齿,使用反锯齿之后的图片和原始图片进行训练,这样前馈时可以得到一个低分变率的高质量图片。然后使用这个图片和高分辨率渲染的图片进行训练,这次则是得到一个高分辨率的高质量图片。当然,即便是AI也不能完美的脑补出不存在的东西,虽然大部分时候效果很好,但有时也会存在一些莫名其妙的缺陷。总体来看的话,AI的实力还是非常厉害的,好于FSR等一般的传统缩放算法,但是它的开销也比一般的缩放算法大,依赖于特殊硬件,而且会引入奇怪的缺陷。
总结
其实如果理解了上面介绍的内容的话,我们可以看到单帧超分辨率和多帧超分辨率是不冲突的,多帧超分辨率在后处理之前实现,而单帧则是后处理的一部分,实际多帧超分辨率的输出可以作为单帧超分辨率的输入。我希望最后能有一个融合两者的技术出现。